
[ad_1]
It solely took twenty 4 hours after Google’s Gemini was publicly launched for somebody to note that chats have been being publicly displayed in Google’s search outcomes. Google rapidly responded to what seemed to be a leak. The explanation how this occurred is kind of stunning and never as sinister because it first seems.
@shemiadhikarath tweeted:
“A number of hours after the launch of @Google Gemini, serps like Bing have listed public conversations from Gemini.”
They posted a screenshot of the positioning search of gemini.google.com/share/
However for those who have a look at the screenshot, you’ll see that there’s a message that claims, “We wish to present you an outline right here however the web site gained’t enable us.”
By early morning on Tuesday February thirteenth the Google Gemini chats started dropping off of Google search outcomes, Google was solely exhibiting three search outcomes. By the afternoon the variety of leaked Gemini chats exhibiting within the search outcomes had dwindled to only one search end result.
How Did Gemini Chat Pages Get Created?
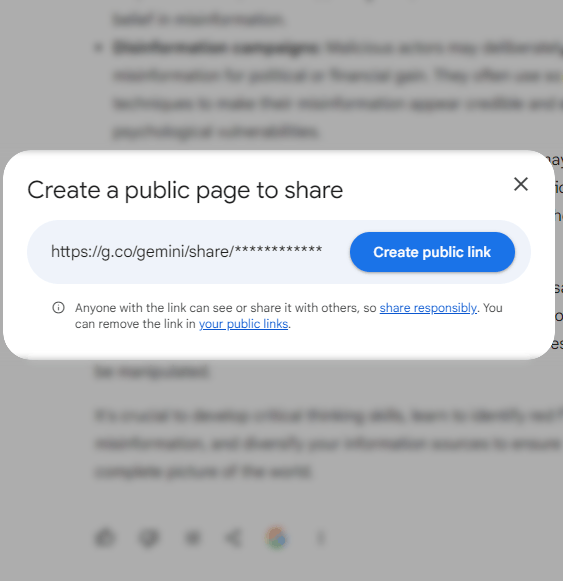
Gemini affords a solution to create a hyperlink to a publicly viewable model of a non-public chat.
Google doesn’t routinely create webpages out of personal chats. Customers create the chat pages by way of a hyperlink on the backside of every chat.
Screenshot Of How To Create a Shared Chat Web page
Why Did Gemini Chat Pages Get Listed?
The apparent cause for why the chat pages have been crawled and listed is as a result of Google forgot to place a robots.txt within the root of the Gemini subdomain, (gemini.google.com).
A robots.txt file is a doc for controlling crawler exercise on web sites. A writer can block particular crawlers through the use of instructions standardized within the Robots.txt Protocol.
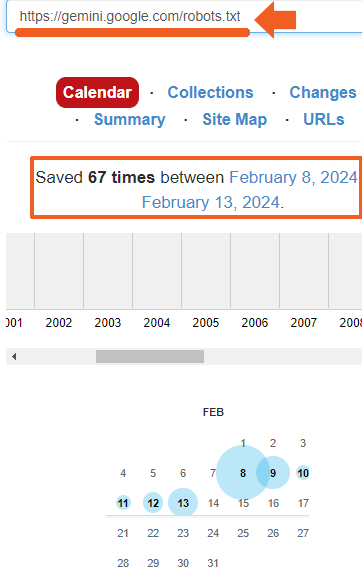
I checked the robots.txt at 4:19 AM on February thirteenth and noticed that one was in place:

I subsequent checked the Web Archive to see how lengthy the robots.txt file has been in place and found that it was there since at the very least February eighth, the day that the Gemini Apps have been introduced.
That signifies that the apparent cause for why the chat pages have been crawled will not be the proper cause, it’s simply the obvious cause.
Though the Google Gemini subdomain had a robots.txt that blocked internet crawlers from each Bing and Google, how did they find yourself crawling these pages and indexing them?
Two Methods Non-public Chat Pages Found And Listed
- There could also be a public hyperlink someplace.
- Much less seemingly however possibly doable is that they have been found by way of searching historical past linked from cookies.
It’s likelier that there’s a public hyperlinks.
I requested Invoice Hartzer about it and he found a public link for one of many listed pages:
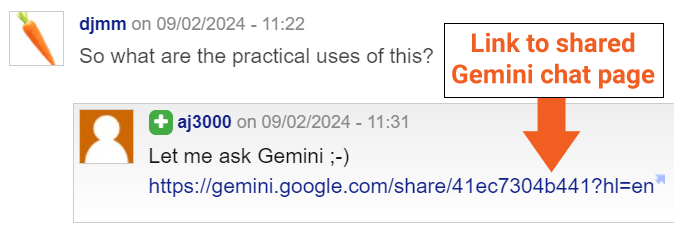
So now we all know that it’s extremely seemingly {that a} public hyperlink prompted these Gemini Chat pages to be crawled and listed.
But when there’s a public hyperlink then why did Google begin dropping chat pages altogether? Did Google create an inner rule for the search crawler to exclude webpages from the /share/ folder from the search index, even when they’re publicly linked?
Insights Into How Bing and Google Search Index Content material
Now right here’s the actually attention-grabbing half for all of the search geeks curious about how Google and Bing index content material.
The Microsoft Bing search index responded to the Gemini content material in another way from how Google search did. Whereas Google was nonetheless exhibiting three search leads to the early morning of February thirteenth, Bing was solely exhibiting one end result from the subdomain. There was a seemingly random high quality to what was listed and the way a lot of it.
Why Did Gemini Chat Pages Leak?
Listed below are the recognized details: Google had a robots.txt in place for the reason that February eighth. Each Google and Bing listed pages from the gemini.google.com subdomain. Google listed the content material whatever the robots.txt after which started dumping them.
- Does Googlebot have a unique directions for indexing content material on Google subdomains?
- Does Googlebot routinely crawl and index content material that’s blocked by robots.txt after which subsequently drop it?
- Was the leaked information linked from someplace that’s crawlable by bots, inflicting the blocked content material to be crawled and listed?
Content material that’s blocked by Robots.txt can nonetheless be found, crawled and find yourself within the search index and ranked within the SERPs or at the very least by way of a web site:search. I feel this can be the case.
But when that’s the case, why did the search outcomes start to drop off?
If the explanation for the crawling and indexing was as a result of these non-public chats have been linked from someplace, was the supply of the hyperlinks eliminated?
The massive query is, the place are these hyperlinks? Might it’s associated to annotations by high quality raters that unintentionally leaked onto the Web?
[ad_2]
Source link