
[ad_1]
Numerous insights and opinions have already been shared about final week’s leak of Google’s Content material API Warehouse documentation, together with the unbelievable write-ups from:
However what can hyperlink builders and digital PRs be taught from the paperwork?
Since information of the leak broke, Liv Day, Digitaloft’s search engine marketing Lead, and I’ve spent lots of time investigating what the documentation tells us about hyperlinks.
We went into our evaluation of the paperwork attempting to achieve insights round just a few key questions:
- Do hyperlinks nonetheless matter?
- Are some hyperlinks extra more likely to contribute to search engine marketing success than others?
- How does Google outline hyperlink spam?
To be clear, the leaked documentation doesn’t include confirmed rating elements. It accommodates data on greater than 2,500 modules and over 14,000 attributes.
We don’t know the way these are weighted, that are utilized in manufacturing and which may exist for experimental functions.
However that doesn’t imply the insights we achieve from these aren’t helpful. As long as we think about any findings to be issues that Google may be rewarding or demoting somewhat than issues they are, we are able to use them to kind the premise of our personal checks and are available to our personal conclusions about what’s or isn’t a rating issue.
Beneath are the issues we discovered within the paperwork that hyperlink builders and digital PRs ought to pay shut consideration to. They’re based mostly by myself interpretation of the documentation, alongside my 15 years of expertise as an search engine marketing.
1. Google might be ignoring hyperlinks that don’t come from a related supply
Relevancy has been the most popular matter in digital PR for a very long time, and one thing that’s by no means been straightforward to measure. In any case, what does relevancy actually imply?
Does Google ignore hyperlinks that don’t come from inside related content material?
The leaked paperwork positively counsel that that is the case.
We see a transparent anchorMismatchDemotion referenced within the CompressedQualitySignals module:

Whereas we now have little further context, what we are able to infer from that is that there’s the power to demote (ignore) hyperlinks when there’s a mismatch. We are able to assume this to imply a mismatch between the supply and goal pages, or the supply web page and goal area.
What may the mismatch be, apart from relevancy?
Particularly once we think about that, in the identical module, we additionally see an attribute of topicEmbeddingsVersionedData.

Matter embeddings are generally utilized in pure language processing (NLP) as a method of understanding the semantic which means of matters inside a doc. This, within the context of the documentation, means webpages.
We additionally see a webrefEntities attribute referenced within the PerDocData module.

What’s this? It’s the entities related to a doc.
We are able to’t make certain precisely how Google is measuring relevancy, however we could be fairly sure that the anchorMismatchDemotion entails ignoring hyperlinks that don’t come from related sources.
The takeaway?
Relevancy must be the most important focus when incomes hyperlinks, prioritized over just about some other metric or measure.
2. Regionally related hyperlinks (from the identical nation) are in all probability extra helpful than ones from different international locations
The AnchorsAnchorSource module, which supplies us an perception into what Google shops concerning the supply web page of hyperlinks, means that native relevance may contribute to the hyperlink’s worth.
Inside this doc is an attribute referred to as localCountryCodes, which shops the international locations to which the web page is native and/or probably the most related.

It’s lengthy been debated in digital PR whether or not hyperlinks coming from websites in different international locations and languages are helpful. This provides us some indication as to the reply.
In the beginning, you need to prioritize incomes hyperlinks from websites which are domestically related. And if we take into consideration why Google may weigh these hyperlinks stronger, it makes whole sense.
Regionally related hyperlinks (don’t confuse this with native publications that always safe hyperlinks and protection from digital PR; right here we’re speaking about country-level) usually tend to enhance model consciousness, end in gross sales and be extra correct endorsements.
Nevertheless, I don’t imagine hyperlinks from different locales are dangerous. Greater than these the place the country-level relevancy matches are weighted extra strongly.
3. Google has a sitewide authority rating, regardless of claiming they don’t calculate an authority measure like DA or DR
Possibly the most important shock to most SEOs studying the documentation is that Google has a “website authority” rating, regardless of stating time and time once more that they don’t have any measure that’s like Moz’s Domain Authority (DA) or Ahrefs’ Area Score (DR).
In 2020, Google’s John Mueller said:
- “Simply to be clear, Google doesn’t use Area Authority *in any respect* in relation to Search crawling, indexing, or rating.”
However later that 12 months, did trace at a sitewide measure, saying about Area Authority:
- “I don’t know if I’d name it authority like that, however we do have some metrics which are extra on a website degree, some metrics which are extra on a web page degree, and a few of these site-wide degree metrics may form of map into comparable issues.”
Clear as day, within the leaked paperwork, we see a SiteAuthority rating.

To caveat this, although, we don’t know that that is even remotely in step with DA or DR. It’s additionally seemingly why Google has sometimes answered questions in the best way they’ve about this matter.
Moz’s DA and Ahrefs’ DR are link-based scores based mostly on the standard and amount of hyperlinks.
I’m uncertain that Google’s siteAuthority is solely link-based although, provided that feels nearer to PageRank. I’d be extra inclined to counsel that that is some type of calculated rating based mostly on page-level high quality scores, together with click on knowledge and different NavBoost indicators.
The chances are, regardless of having an analogous naming conference, this doesn’t align with DA and DR, particularly provided that we see this referenced within the CompressedQualitySignals module, not a link-specific one.
4. Hyperlinks from inside newer pages are in all probability extra helpful than these on older ones
One fascinating discovering is that hyperlinks from newer pages look to be weighted extra strongly than these coming from older content material, in some circumstances.
We see reference to sourceType within the context of anchors (hyperlinks), the place the standard of a hyperlink’s supply web page is recorded in correlation to the web page’s index tier.

What stands out right here, although, is the reference to newly printed content material (freshdocs) being a particular case and regarded to be the identical as “top quality” hyperlinks.
We are able to clearly see that the supply kind of a hyperlink can be utilized as an significance indicator, which means that this pertains to how hyperlinks are weighted.
What we should think about, although, is {that a} hyperlink could be outlined as being “top quality” with out being a contemporary web page, it’s simply that these are thought-about the identical high quality.
To me, this backs up the significance of constantly incomes hyperlinks and explains why SEOs proceed to suggest that hyperlink constructing (in no matter kind, that’s not what we’re discussing right here) wants constant sources allotted. It must be an “always-on” exercise.
5. The extra Google trusts a website’s homepage, the extra helpful hyperlinks from that website in all probability are
We see a reference inside the documentation (once more, within the AnchorsAnchorSource module) to an attribute referred to as homePageInfo, which means that Google may very well be tagging hyperlink sources as not trusted, partially trusted or totally trusted.

What this does outline is that this attribute pertains to situations when the supply web page is an internet site’s homepage, with a not_homepage worth being assigned to different pages.
So, what may this imply?
It means that Google may very well be utilizing some definition of “belief” of an internet site’s homepage inside the algorithms. How? We’re unsure.
My interpretation: inner pages are more likely to inherit the homepage’s trustworthiness.
To be clear: we don’t know the way Google defines whether or not a web page is totally trusted, not trusted or partially trusted.
However it could make sense that inner pages inherit a homepage’s trustworthiness and that that is used, to some extent, within the weighting of hyperlinks and that hyperlinks from totally trusted websites are extra helpful than these from not trusted ones.
Apparently, we’ve found that Google is storing further details about a hyperlink when it’s recognized as coming from a “newsy, top quality” website.

Does this imply that hyperlinks from information websites (for instance, The New York Instances, The Guardian or the BBC) are extra helpful than these from different varieties of website?
We don’t know for certain.
However when taking a look at this – alongside the truth that some of these websites are sometimes probably the most authoritative and trusted publications on-line, in addition to those who would traditionally had a toolbar PageRank of 9 or 10 – it does make you assume.
What’s for certain, although, is that leveraging digital PR as a tactic to earn hyperlinks from information publications is undoubtedly extremely helpful. This discovering simply confirms that.
7. Hyperlinks coming from seed websites, or these hyperlinks to from these, are in all probability probably the most helpful hyperlinks you could possibly earn
Seed websites and hyperlink distance rating is a subject that doesn’t get talked about anyplace close to as usually because it ought to, for my part.
It’s nothing new, although. Actually, it’s one thing that the late Bill Slawski wrote about in 2010, 2015 and 2018.
The leaked Google documentation means that PageRank in its authentic kind has lengthy been deprecated and changed by PageRank-NearestSeeds, referenced by the very fact it defines this because the manufacturing PageRank worth for use. That is maybe one of many issues that the documentation is the clearest on.

Should you’re unfamiliar with seed websites, the excellent news is that it isn’t a massively advanced idea to grasp.
Slawski’s articles on this matter are in all probability the very best reference level for this:
“The patent offers 2 examples [of seed sites]: The Google Listing (It was nonetheless round when the patent was first filed) and the New York Instances. We’re additionally informed: ‘Seed units should be dependable, numerous sufficient to cowl a variety of fields of public pursuits & properly related to different websites. As well as, they need to have giant numbers of helpful outgoing hyperlinks to facilitate figuring out different helpful & high-quality pages, appearing as ‘hubs’ on the net.’
“Beneath the PageRank patent, rating scores are given to pages based mostly upon how far-off they is likely to be from these seed units and based mostly upon different options of these pages.”– Invoice Slawski, PageRank Update (2018)
8. Google might be utilizing ‘trusted sources’ to calculate whether or not a hyperlink is spammy
When wanting on the IndexingDocjoinerAnchorSpamInfo module, one which we are able to assume pertains to how spammy hyperlinks are processed, we see references to “trusted sources.”

It appears like Google can calculate the likelihood of hyperlink spam based mostly on the variety of trusted sources linking to a web page.
We don’t know what constitutes a “trusted supply,” however when checked out holistically alongside our different findings, we are able to assume that this may very well be based mostly on the “homepage” belief.
Can hyperlinks from trusted sources successfully dilute spammy hyperlinks?
It’s positively potential.
9. Google might be figuring out destructive search engine marketing assaults and ignoring these hyperlinks by measuring hyperlink velocity
The search engine marketing group has been divided over whether or not destructive search engine marketing assaults are an issue for a while. Google is adamant they’re in a position to determine such assaults, whereas loads of SEOs have claimed their website was negatively impacted by this concern.
The documentation offers us some perception into how Google makes an attempt to determine such assaults, together with attributes that think about:
- The timeframe over which spammy hyperlinks have been picked up.
- The typical day by day fee of spam found.
- When a spike began.

It’s potential that this additionally considers hyperlinks meant to control Google’s rating methods, however the reference to “the anchor spam spike” means that that is the mechanism for figuring out important volumes, one thing we all know is a standard concern confronted with destructive search engine marketing assaults.
There are seemingly different elements at play in figuring out how hyperlinks picked up throughout a spike are ignored, however we are able to not less than begin to piece collectively the puzzle of how Google is attempting to stop such assaults from having a destructive affect on websites.
10. Hyperlink-based penalties or changes can seemingly apply both to some or the entire hyperlinks pointing to a web page
Plainly Google has the power to use hyperlink spam penalties or ignore hyperlinks on a link-by-link or all-links foundation.

This might imply that, given a number of unconfirmed indicators, Google can outline whether or not to disregard all hyperlinks pointing to a web page or simply a few of them.
Does this imply that, in circumstances of extreme hyperlink spam pointing to a web page, Google can choose to disregard all hyperlinks, together with those who would usually be thought-about top quality?
We are able to’t make certain. However if so, it may imply that spammy hyperlinks are usually not the one ones ignored when they’re detected.
May this negate the affect of all hyperlinks to a web page? It’s positively a chance.
11. Poisonous hyperlinks are a factor, regardless of Google saying they aren’t
Simply final month, Mueller said (once more) that toxic links are a made-up concept:
- “The idea of poisonous hyperlinks is made up by search engine marketing instruments so that you just pay them often.”
Within the documentation, although, we see reference given to “BadBackLinks.”

The data given right here suggests {that a} web page could be penalized for having “unhealthy” backlinks.
Whereas we don’t know what kind this takes or how shut that is to the poisonous hyperlink scores given by search engine marketing instruments, we’ve obtained loads of proof to counsel that there’s not less than a boolean (sometimes true or false values) measure of whether or not a web page has unhealthy hyperlinks pointing to it.
My guess is that this works together with the hyperlink spam demotions I talked about above, however we don’t know for certain.
12. The content material surrounding a hyperlink offers context alongside the anchor textual content
SEOs have lengthy leveraged the anchor textual content of hyperlinks as a solution to give contextual indicators of the goal web page, and Google’s Search Central documentation on link best practices confirms that “this textual content tells folks and Google one thing concerning the web page you’re linking to.”
However final week’s leaked paperwork point out that it’s not simply anchor textual content that’s used to grasp the context of a hyperlink. The content material surrounding the hyperlink is probably going additionally used.

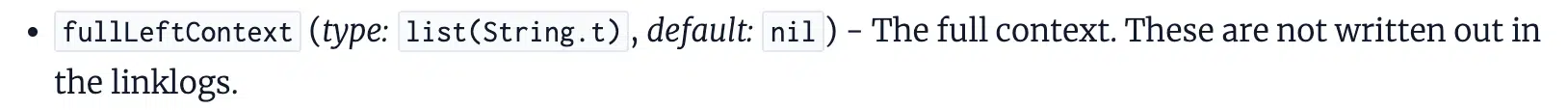

The documentation references context2, fullLeftContext, and fullRightContext, that are the phrases close to the hyperlink.
This means that there’s greater than the anchor textual content of a hyperlink getting used to find out the relevancy of a hyperlink. On one hand, it may merely be used as a solution to take away ambiguity, however on the opposite, it may very well be contributing to the weighting.
This feeds into the overall consensus that hyperlinks from inside related content material are weighted way more strongly than these inside content material that’s not.
Key learnings & takeaways for hyperlink builders and digital PRs
Do hyperlinks nonetheless matter?
I’d actually say so.
There’s an terrible lot of proof right here to counsel that hyperlinks are nonetheless important rating indicators (regardless of us not understanding what’s and isn’t a rating sign from this leak), however that it’s not nearly hyperlinks normally.
Hyperlinks that Google rewards or doesn’t ignore usually tend to positively affect natural visibility and rankings.
Possibly the most important takeaway from the documentation is that relevancy issues so much. It’s seemingly that Google ignores hyperlinks that don’t come from related pages, making this a precedence measure of success for hyperlink builders and digital PRs alike.
However past this, we’ve gained a deeper understanding of how Google doubtlessly values hyperlinks and the issues that may very well be weighted extra strongly than others.
Ought to these findings change the best way you method hyperlink constructing or digital PR?
That will depend on the techniques you’re utilizing.
Should you’re nonetheless utilizing outdated techniques to earn lower-quality hyperlinks, then I’d say sure.
But when your hyperlink acquisition techniques are based mostly on incomes hyperlinks with PR techniques from high-quality press publications, the principle factor is to be sure you’re pitching related tales, somewhat than assuming that any hyperlink from a excessive authority publication will probably be rewarded.
For many people, not a lot will change. Nevertheless it’s a concrete affirmation that the techniques we’re counting on are the very best match, and the rationale behind why we see PR-earned hyperlinks having such a constructive affect on natural search success.
Opinions expressed on this article are these of the visitor creator and never essentially Search Engine Land. Workers authors are listed here.
[ad_2]
Source link