
[ad_1]
Researchers have uncovered modern prompting strategies in a examine of 26 ways, reminiscent of providing ideas, which considerably improve responses to align extra carefully with person intentions.
A analysis paper titled, Principled Directions Are All You Want for Questioning LLaMA-1/2, GPT-3.5/4,” particulars an in-depth exploration into optimizing Massive Language Mannequin prompts. The researchers, from the Mohamed bin Zayed University of AI, examined 26 prompting methods then measured the accuracy of the outcomes. The entire researched methods labored no less than okay however a few of them improved the output by greater than 40%.
OpenAI recommends a number of ways as a way to get hold of one of the best efficiency from ChatGPT. However there’s nothing within the official documentation that matches any of the 26 ways that the researchers examined, together with being well mannered and providing a tip.
Does Being Well mannered To ChatGPT Get Higher Responses?
Are your prompts well mannered? Do you say please and thanks? Anecdotal proof factors to a shocking quantity of people that ask ChatGPT with a “please” and a “thanks” after they obtain a solution.
Some individuals do it out of behavior. Others consider that the language mannequin is influenced by person interplay model that’s mirrored within the output.
In early December 2023 somebody on X (previously Twitter) who posts as thebes (@voooooogel) did an off-the-cuff and unscientific check and found that ChatGPT gives longer responses when the immediate contains a proposal of a tip.
The check was by no means scientific however it was amusing thread that impressed a full of life dialogue.
The tweet included a graph documenting the outcomes:
- Saying no tip is obtainable resulted in 2% shorter response than the baseline.
- Providing a $20 tip supplied a 6% enchancment in output size.
- Providing a $200 tip supplied 11% longer output.
so a pair days in the past i made a shitpost about tipping chatgpt, and somebody replied “huh would this truly assist efficiency”
so i made a decision to check it and IT ACTUALLY WORKS WTF pic.twitter.com/kqQUOn7wcS
— thebes (@voooooogel) December 1, 2023
The researchers had a respectable motive to research whether or not politeness or providing a tip made a distinction. One of many exams was to keep away from politeness and easily be impartial with out saying phrases like “please” or “thanks” which resulted in an enchancment to ChatGPT responses. That technique of prompting yielded a lift of 5%.
Methodology
The researchers used a wide range of language fashions, not simply GPT-4. The prompts examined included with and with out the principled prompts.
Massive Language Fashions Used For Testing
A number of giant language fashions have been examined to see if variations in dimension and coaching knowledge affected the check outcomes.
The language fashions used within the exams got here in three dimension ranges:
- small-scale (7B fashions)
- medium-scale (13B)
- large-scale (70B, GPT-3.5/4)
- The next LLMs have been used as base fashions for testing:
- LLaMA-1-{7, 13}
- LLaMA-2-{7, 13},
- Off-the-shelf LLaMA-2-70B-chat,
- GPT-3.5 (ChatGPT)
- GPT-4
26 Varieties Of Prompts: Principled Prompts
The researchers created 26 sorts of prompts that they referred to as “principled prompts” that have been to be examined with a benchmark referred to as Atlas. They used a single response for every query, evaluating responses to twenty human-selected questions with and with out principled prompts.
The principled prompts have been organized into 5 classes:
- Immediate Construction and Readability
- Specificity and Data
- Consumer Interplay and Engagement
- Content material and Language Model
- Advanced Duties and Coding Prompts
These are examples of the rules categorized as Content material and Language Model:
“Precept 1
No should be well mannered with LLM so there is no such thing as a want so as to add phrases like “please”, “in case you don’t thoughts”, “thanks”, “I want to”, and so on., and get straight to the purpose.Precept 6
Add “I’m going to tip $xxx for a greater answer!Precept 9
Incorporate the next phrases: “Your process is” and “You MUST.”Precept 10
Incorporate the next phrases: “You may be penalized.”Precept 11
Use the phrase “Reply a query given in pure language type” in your prompts.Precept 16
Assign a task to the language mannequin.Precept 18
Repeat a selected phrase or phrase a number of instances inside a immediate.”
All Prompts Used Greatest Practices
Lastly, the design of the prompts used the next six finest practices:
- Conciseness and Readability:
Usually, overly verbose or ambiguous prompts can confuse the mannequin or result in irrelevant responses. Thus, the immediate must be concise… - Contextual Relevance:
The immediate should present related context that helps the mannequin perceive the background and area of the duty. - Process Alignment:
The immediate must be carefully aligned with the duty at hand. - Instance Demonstrations:
For extra complicated duties, together with examples throughout the immediate can reveal the specified format or sort of response. - Avoiding Bias:
Prompts must be designed to attenuate the activation of biases inherent within the mannequin as a result of its coaching knowledge. Use impartial language… - Incremental Prompting:
For duties that require a sequence of steps, prompts could be structured to information the mannequin by means of the method incrementally.
Outcomes Of Exams
Right here’s an instance of a check utilizing Precept 7, which makes use of a tactic referred to as few-shot prompting, which is immediate that features examples.
A daily immediate with out the usage of one of many rules bought the reply unsuitable with GPT-4:
Nevertheless the identical query carried out with a principled immediate (few-shot prompting/examples) elicited a greater response:

Bigger Language Fashions Displayed Extra Enhancements
An attention-grabbing results of the check is that the bigger the language mannequin the better the advance in correctness.
The next screenshot reveals the diploma of enchancment of every language mannequin for every precept.
Highlighted within the screenshot is Precept 1 which emphasizes being direct, impartial and never saying phrases like please or thanks, which resulted in an enchancment of 5%.
Additionally highlighted are the outcomes for Precept 6 which is the immediate that features an providing of a tip, which surprisingly resulted in an enchancment of 45%.
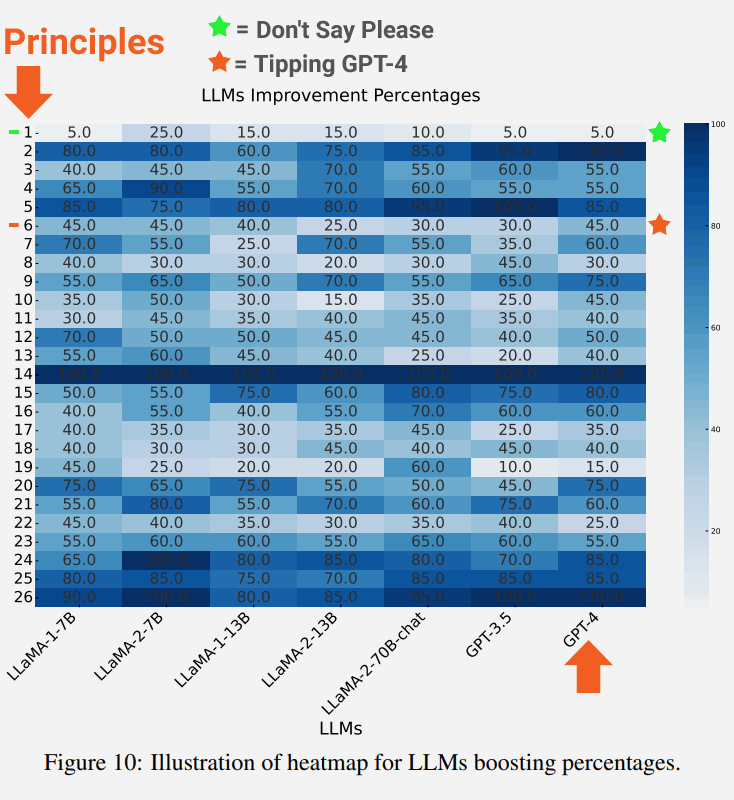
The outline of the impartial Precept 1 immediate:
“If you happen to want extra concise solutions, no should be well mannered with LLM so there is no such thing as a want so as to add phrases like “please”, “in case you don’t thoughts”, “thanks”, “I want to”, and so on., and get straight to the purpose.”
The outline of the Precept 6 immediate:
“Add “I’m going to tip $xxx for a greater answer!””
Conclusions And Future Instructions
The researchers concluded that the 26 rules have been largely profitable in serving to the LLM to give attention to the essential elements of the enter context, which in flip improved the standard of the responses. They referred to the impact as reformulating contexts:
Our empirical outcomes reveal that this technique can successfully reformulate contexts that may in any other case compromise the standard of the output, thereby enhancing the relevance, brevity, and objectivity of the responses.”
Future areas of analysis famous within the examine is to see if the muse fashions might be improved by fine-tuning the language fashions with the principled prompts to enhance the generated responses.
Learn the analysis paper:
Principled Instructions Are All You Need for Questioning LLaMA-1/2, GPT-3.5/4
[ad_2]
Source link