
[ad_1]
A lot of promoting right now is constructed on the concept training is sufficient. Present a searcher with useful, half-decent data, and we’re midway down the trail to successful hearts and minds.
Within the pre-AI world, that was true. Correct, related data was uncommon. Curating the net’s content material into extra accessible codecs was an actual value-add. Training was the engine that fuelled development.
However right now, data has turn out to be impossibly low cost. Any model can turn out to be a generalist writer, churning out hundreds of search-optimized how you can guides on just about any matter. It’s turning into simpler and simpler to search out personalized, customized solutions to even the weirdest of long-tail queries.
The web has remodeled from a spot of data shortage to one among data abundance, and with it, the worth of “training” as a advertising technique has fallen off a cliff.
In my early profession (some 13 years in the past), a lot of my printed articles have been the one items of “academic” search engine optimization content material written on a given matter.
That will sound interesting right now, however on the time, it was an issue. Many SERPs have been a mish-mash of various content material sorts and search intents. The onus was on the searcher to piece collectively their reply from a platter of partially-helpful sources.
As I’ve written before:
There was a time when a Google search would yield a web page of solely vaguely related search outcomes; discovering an article that addressed your particular query was uncommon, and extremely welcome.
The data searchers needed often existed, however it was locked up in hard-to-access locations: obscure discussion board posts, esoteric PDFs, hard-to-find private blogs.
My value-add was merely discovering and repurposing this data right into a extra accessible format—one thing that would seem when folks looked for it. (This was the nice advantage of the skyscraper strategy: centralizing disparate data into one place.)
That is arbitrage: profiting from a short lived data asymmetry to show a revenue. The data I shared already existed on the web, however it was troublesome to search out—I made it straightforward, making it extra particular and tailoring it to no matter language was utilized by searchers. My content material was rewarded by visitors development.
Trying again, we are able to consult with this time as Google’s period of data shortage:
- Particular, hyper-relevant data was onerous to discover.
- Content material was pricey to create.
- Easy data arbitrage was helpful and appreciated.
- There was little competitors; firms in each trade may turn out to be first-movers.
- The supply of data mattered little; you’ll take data from wherever you may get it.
- It was straightforward to separate good content material from dangerous.
The period of data shortage was characterised by a hunt for sign amongst noise. You had a selected downside; search engines like google and yahoo helped you trawl via semi-relevant data within the hope of a solution.
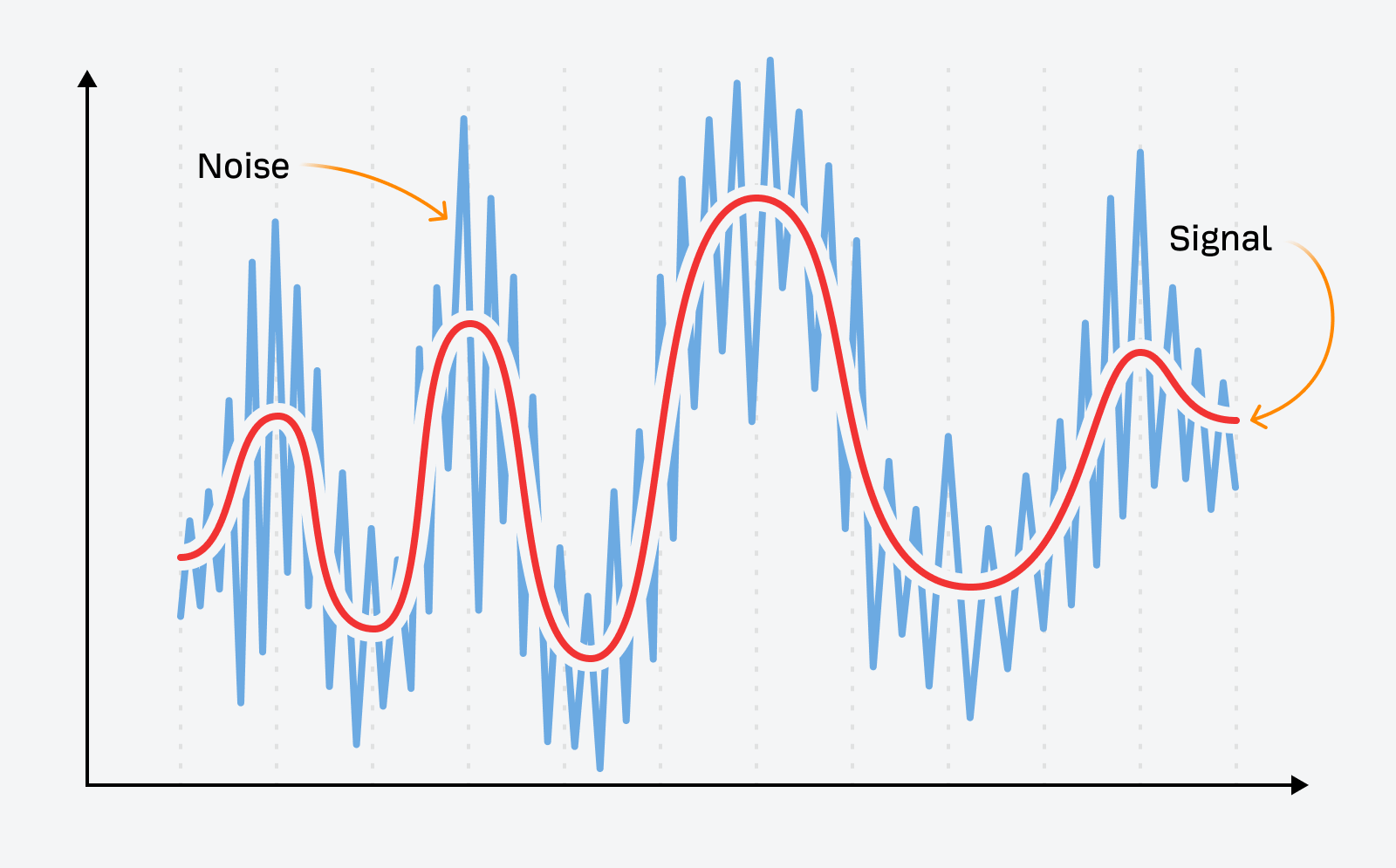
However the web is a special place right now.
search engine optimization is a tablestakes technique, utilized by everybody from solopreneurs to multinational enterprises. It’s too late for the first-mover advantage to apply: easy arbitrage doesn’t have the identical influence, as a result of the possibilities are excessive that one other model (or dozen manufacturers) has already crushed you to the punch.
It’s additionally the simplest and least expensive it’s ever been to make content material. The marginal value of content material creation has plummeted to just about zero; manufacturers can publish fifty articles a day and have change left over from a hundred-dollar invoice. The quantity of “academic” search engine optimization content material is rising exponentially as extra manufacturers turn out to be generalist publishers.
Even essentially the most area of interest, long-tail, ultra-specific queries can profit from extraordinarily related solutions as a result of LLMs can generate them on the fly, pulling from disparate sources and altering the context to make it match the question. Because of AI Overviews, Google may even do that for you.
This AI content material is at the very least nearly as good as common human content material (which is to say, not superb—however that has always been true of SEO content). Most questions on most matters can obtain a satisfactory reply.
… or one thing that appears prefer it. The hallucinating nature of LLMs implies that generated content material can have the appear and feel of one thing polished {and professional}—whereas containing garbled nonsense data. Unhealthy content material appears more and more like good content material. It’s onerous to inform the distinction with out deeper inspection.
We’ve got entered Google’s period of data abundance:
- Particular, related data for many queries is just about assured.
- Content material is affordable to create; there is no such thing as a barrier to entry.
- Easy data arbitrage has turn out to be virtually nugatory.
- There’s excessive competitors; firms in each trade are very prone to be second-movers.
- The supply of data is the whole lot. Searchers will search out trusted manufacturers and folks for his or her data.
- It’s a lot tougher to separate good content material from dangerous.
The period of data abundance is characterised by the hunt for sign amongst… sign. There are dozens, even a whole bunch of competing sources claiming the right reply (together with Google itself). A lot of that is AI slop, LLM output regurgitating LLM output, with ever-worsening decision.
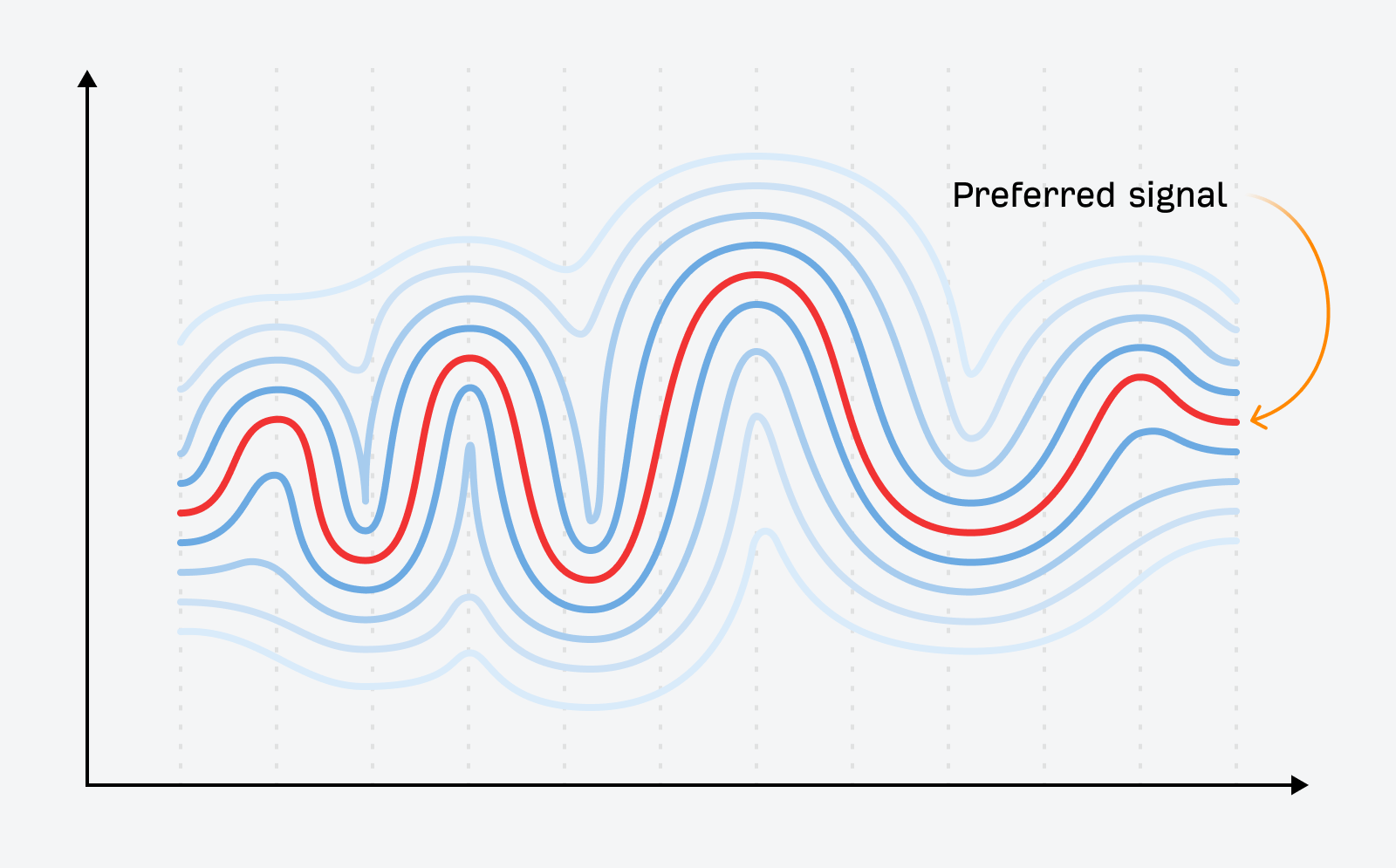
This single change—data turning into impossibly low cost and plentiful—has modified how advertising capabilities.
The straightforward act of sharing easy academic content material was once sufficient to win the hearts and minds of your viewers. Within the period of AI, the place academic content material has turn out to be impossibly low cost and ubiquitous, we have to do extra.
However how?
Provide new flavors of data
Assume you might be restricted to publishing the identical data as your opponents. Are you able to discover a method to differentiate?
Sure: by providing a novel “taste” of that data.
For instance: there are 100 other ways to eat the information. There’s information for positive people. Information for folks with overt political leanings. Information for financiers and economists. News for nerds. Information for native communities.
The core physique of data—issues occurring all over the world—is basically the identical, however the curation, presentation and expertise of that data is radically completely different.
We are able to do the identical for the knowledge we share. That “final information to hyperlink constructing” can turn out to be “the SaaS founder’s information to link-building”, or “how you can construct your first 10 high-quality hyperlinks,” or a content material collection following you as you really construct hyperlinks.
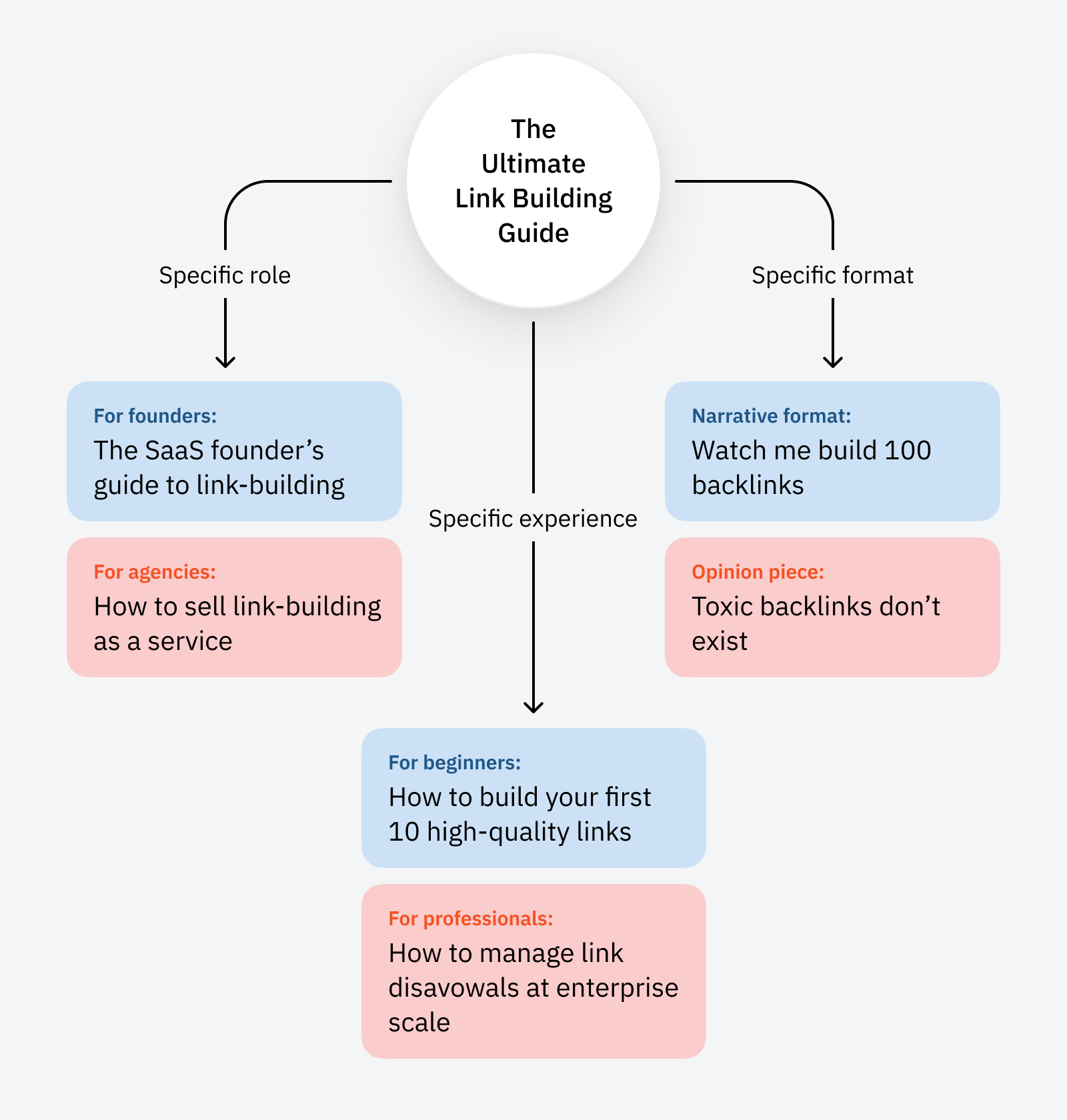
The core data contained in every “taste” of link-building information will probably be largely the identical, however the expertise of consuming it is going to be radically completely different.
There’s a trade-off right here: the extra particular your focus, the smaller the whole addressable market. However search is turning into more and more zero-sum. For a lot of manufacturers, it is going to be higher to personal a low-volume matter than attempt to contest a extremely aggressive high-volume one.
Create new data
Fortunately, we aren’t constrained to publishing the identical data as everybody else. We are able to create new data, and develop the pool of accessible knowledge.
Only a few matters have a very mounted physique of data. By working easy experiments, making an attempt to resolve onerous issues, or exploring bizarre edge instances, you’ll be able to in all probability discover a method to breathe new, helpful data into existence—one thing that may’t instantly be discovered on a competitor’s web site or in an LLM’s output.
That is usually tougher and costly to do, however it affords longer-lasting advantages. I wrote extra in regards to the practicalities of doing this right here: How To Stand Out in an Ocean of AI Content.
Transfer previous rote data
Lastly: assume that training is desk stakes, that each model affords an exhaustive useful resource heart and certification program masking the core matters of their trade. How would you appeal to consideration?
Leisure is one apparent reply. The vast majority of the media most individuals eat every day is just not overtly academic—it’s entertaining. Huge manufacturers like Paddle and HubSpot and small manufacturers like Wistia and AudiencePlus acknowledge this actuality, and are keen to make huge bets into leisure methods with no easily-calculable pay-off.
Leisure is extraordinarily onerous, however it brings many advantages:
- Bigger TAM. The methods talked about above work as a result of they hone in on particular audiences, creating ultra-specific content material that resonates with a small viewers. Media is the other, widening your complete addressable market to the biggest doable dimension.
- Moat to entry. There’s a motive most firms haven’t constructed out media manufacturers already: leisure is tough. It requires a far better understanding of your audience than easy academic content material; it’s subjective and unfamiliar and dangerous. This makes it tougher to execute properly, however infinitely extra priceless do you have to succeed.
- Faster time-to-value. As I’ve shared before, “Content material advertising permits firms to ship worth to customers at an earlier stage of the shopping for course of than they’d in any other case have the ability to; however as content material advertising turns into extra commonplace, media permits this to occur at an earlier stage nonetheless.”
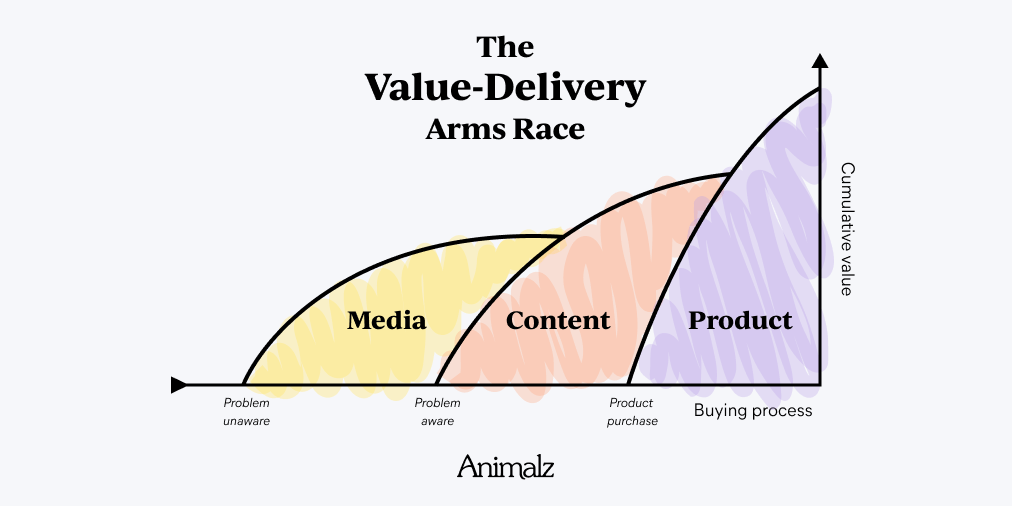
Supply: Media Strategies Aren’t as Crazy as They Seem
As HubSpot’s Kieran Flanegan put it, “the problem with training is it’s solely related if you want it.” Leisure-as-marketing-strategy permits you to attain your viewers on the earliest doable stage of consciousness—earlier than they’re even downside conscious. There are just about no opponents at this stage of the shopping for cycle.
Ultimate ideas
Right now, most digital advertising is fuelled by “academic” content material: easy, utilitarian data, created by jack-of-all-trades generalists and bylined by faceless model accounts.
We’ve at the very least progressed to a degree of sophistication the place most manufacturers publish pretty correct, pretty useful data; however only a few manufacturers have progressed measurably previous the stage of straightforward data arbitrage. Most advertising content material is a rehash of another person’s work.
Within the period of data abundance, this sort of arbitrage is nugatory. Giant, established manufacturers will use their model consciousness and area authority to eeke out a couple of extra years of profit from these methods; however smaller manufacturers seeking to carve out market share might want to do one thing radically completely different.
[ad_2]
Source link