
[ad_1]
The mere point out of math can carry again haunting recollections of unfinished exams and sophisticated equations. However what if I advised you that the maths we’re about to discover confirms a number of what you already intuitively learn about SEO?
As SEOs, we regularly have hunches about what components affect rankings. Perhaps you’ve seen that pages with extra backlinks are likely to rank greater or that faster-loading websites appear to carry out higher in search outcomes.
In the present day, we are going to have a look at mathematical instruments that may assist us validate (or typically problem) these hunches. By the top of this text, you’ll see how these instruments will allow you to separate search engine optimisation truth from fiction and enhance your confidence in recommending methods.
The worth of utilized arithmetic in search engine optimisation
Within the 1985 research “Usefulness of Analogous Options for Fixing Algebra Phrase Issues,” researchers discovered that college students usually struggled to use mathematical ideas to related issues, not to mention to real-life conditions the place these ideas may very well be useful.
This issue arises as a result of these ideas are usually discovered in isolation. By seeing how these ideas are utilized in particular, real-life contexts, college students can start to acknowledge extra alternatives to make use of them virtually.
In the present day, by inspecting these instruments within the context of search engine optimisation, we will begin to establish different search engine optimisation situations that will profit from making use of mathematical ideas.
At my company, we apply correlation evaluation in a number of important areas:
- The function of high quality vs. amount of referring domains in a given {industry}.
- The connection between content material and site visitors. Is the amount of content material vital in an {industry}?
- The significance of varied rating components in particular SERP consequence pages. How vital are referring domains to a selected consequence?

The promise and limitations of correlation evaluation in search engine optimisation
If we’re assured that the Google algorithm has sure rating options, may we simply use correlation evaluation of search outcomes to see their affect?
Like most search engine optimisation questions, the reply is “it relies upon.”
Figuring out the function of rating components and their significance for a SERP is difficult as a result of completely different rating components could not correspond to rankings in a linear or constantly growing/reducing method.
For instance, think about the influence of web page load velocity on rankings. A web site would possibly see important rating enhancements when decreasing load time from 10 seconds to 3 seconds, however additional enhancements from three seconds to 1 second would possibly yield diminishing returns.
On this case, the connection between web page velocity and rankings isn’t linear — there’s a threshold the place the influence turns into much less pronounced, making it difficult to precisely assess its significance utilizing easy correlation strategies.
Earlier than we dive into analyzing particular rating components for a SERP, we have to perceive the fundamentals of correlation and which technique would give us one of the best outcomes and for which rating components. You’ll rapidly study that regardless that we use arithmetic, area experience and our expectations about information play a important function in utilizing arithmetic successfully.
Dig deeper: How research on learning can help you understand advanced SEO concepts
So, what’s correlation? Let’s go over the 2 hottest methods.
Pearson correlation in search engine optimisation
Pearson correlation appears to be like for straight-line relationships between two components. In search engine optimisation, this is likely to be helpful for components that have a tendency to extend or lower steadily with rankings.
Instance: Let’s have a look at the connection between content material size and search engine rankings for a selected key phrase.
- Rank 1: 2000 phrases
- Rank 2: 1800 phrases
- Rank 3: 1600 phrases
- Rank 4: 1400 phrases
- Rank 5: 1200 phrases
Run Python code
import numpy as np
from scipy.stats import pearsonr
# Knowledge
ranks = [1, 2, 3, 4, 5]
word_counts = [2000, 1800, 1600, 1400, 1200]
# Calculate Pearson correlation
correlation, p_value = pearsonr(ranks, word_counts)
print(f"Pearson correlation coefficient: {correlation}")
print(f"P-value: {p_value}")On this instance, we see an ideal Pearson correlation. Because the content material size decreases, the rating place steadily will increase (will get worse). Every drop of 200 phrases corresponds to a drop of 1 rating place.
(In mathematical phrases, this might be an ideal unfavorable linear correlation with a worth of -1.)
Nonetheless, actual search engine optimisation information isn’t this good. If the web page at Rank 3 had 1,750 phrases as a substitute of 1,600, we’d nonetheless have a robust correlation, but it surely wouldn’t be good.
Pearson correlation in search engine optimisation is most helpful after we count on an element to have a constant, linear relationship with rankings.
Helpful tip on statistical significance
The “30 rule” for Pearson correlation means that for a correlation to be statistically important, a pattern dimension of not less than 30 is often wanted.
That is based mostly on the Central Restrict Theorem, which states that with a sufficiently giant pattern dimension (n ≥ 30), the sampling distribution of the correlation coefficient can be roughly usually distributed, permitting for extra dependable and legitimate significance testing.
Spearman correlation in search engine optimisation
Spearman correlation is usually extra helpful in search engine optimisation as a result of it examines whether or not one issue tends to extend as one other will increase (or decreases), even when the connection isn’t completely regular. The great thing about Spearman is that it’s only a Pearson correlation on ranked information.
Instance: Let’s have a look at the connection between a web page’s Ahrefs Area Ranking (DR) and its rating for a selected key phrase.
- Rank 1: DR 85
- Rank 2: DR 78
- Rank 3: DR 72
- Rank 4: DR 65
- Rank 5: DR 45
Now, let’s convert this to ranked information:
Step 1: Rank the DR values (highest to lowest):
- 85 (Rank 1)
- 78 (Rank 2)
- 72 (Rank 3)
- 65 (Rank 4)
- 45 (Rank 5)
Step 2: Pair the DR ranks with the SERP ranks:
- SERP Rank 1: DR Rank 1
- SERP Rank 2: DR Rank 2
- SERP Rank 3: DR Rank 3
- SERP Rank 4: DR Rank 4
- SERP Rank 5: DR Rank 5
Run Python code
from scipy.stats import spearmanr
# Knowledge
serp_ranks = [1, 2, 3, 4, 5]
dr_ranks = [1, 2, 3, 4, 5]
# Calculate Spearman correlation
spearman_correlation, spearman_p_value = spearmanr(serp_ranks, dr_ranks)
print(f"Spearman correlation coefficient: {spearman_correlation}")
print(f"P-value: {spearman_p_value}")On this case, we find yourself with an ideal Spearman correlation, regardless that the unique information wasn’t completely linear. The Spearman correlation appears to be like on the relationship between these ranks, fairly than the uncooked values.
Right here’s why that is highly effective: Even when the unique DR values have been wildly completely different (say, 1000, 500, 200, 100, 50), so long as they maintained the identical order relative to the SERP rankings, the Spearman correlation could be the identical.
This method helps easy out non-linear relationships and reduces the influence of outliers. In search engine optimisation, the place many components don’t have a wonderfully linear relationship with rankings, Spearman correlation usually provides us a clearer image of the overall tendencies.
(In technical phrases, Spearman correlation appears to be like on the monotonic relationship between variables utilizing ranked information fairly than uncooked values.)
Utilizing this rating technique, Spearman correlation can seize tendencies that Pearson would possibly miss, making it worthwhile in our search engine optimisation evaluation toolkit.
Making use of correlation to search engine optimisation rating components
With correlation, we will start to assume via a fundamental rating heuristic for a given search consequence. For instance, let’s think about a fundamental method like this:
We are able to begin making educated guesses in regards to the weights (w1, w2, w3, and so forth.) of those components based mostly on correlation evaluation.
The multitude of rating components
Google’s algorithm is extremely advanced, with lots of of rating components at play. As SEOs, we regularly discover ourselves making an attempt to decipher which of those components are essentially the most essential.
Over time, via a mix of expertise, testing and official Google statements, we usually develop an inventory of 10-20 components that we consider are essentially the most impactful.
This record would possibly embrace parts like:
- Content material high quality and relevance.
- Backlink profile (amount and high quality).
- Consumer expertise alerts.
- Web page velocity.
- Cell-friendliness.
- Key phrase utilization and optimization.
- Content material freshness.
- SSL safety.
- Schema markup.
Whereas this record isn’t exhaustive, it provides us a place to begin for our correlation evaluation.
Get the each day newsletter search entrepreneurs depend on.
Kinds of rating components and what we’d count on
Let’s dive deeper into how various kinds of rating components would possibly behave in our evaluation.
Growing components
These are components the place we typically count on that extra is best. For instance, with referring domains, we’d usually count on that websites with extra high-quality backlinks would rank greater.
If this issue is critical, we’d see a robust unfavorable correlation between the variety of referring domains and rating place (keep in mind, decrease rating numbers are higher).
- Anticipated correlation: Because the variety of referring domains will increase, rating place decreases (improves).
Linear rating components
These components are likely to have a extra easy relationship with rankings. Content material size may very well be an instance right here. If it’s a major issue, we would see a constant relationship the place longer content material correlates with higher rankings, up to some extent.
- Anticipated correlation: As content material size will increase, rating place decreases (improves) in a comparatively constant method.
Reducing rating relationships
These are components the place decrease values are typically higher. Web site velocity is a basic instance. We’d count on faster-loading websites to rank greater.
- Anticipated correlation: As web page load time decreases, rating place decreases (improves).
Binary rating components
These are sure/no components, like whether or not a web site has SSL or not. For these, we would have a look at the proportion of top-ranking websites which have the issue in comparison with lower-ranking websites.
- Anticipated sample: A better proportion of top-ranking websites would have the issue in comparison with lower-ranking websites.
Threshold-based and non-linear components
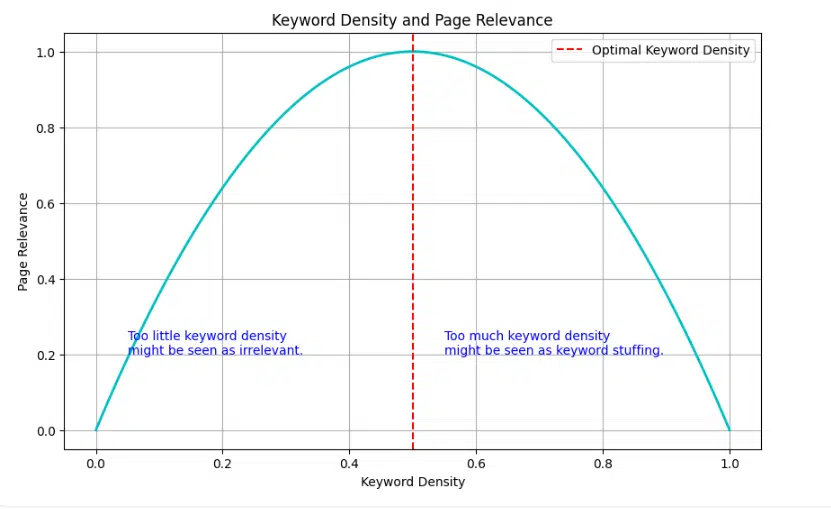
These are maybe the trickiest to research with easy correlation. Key phrase density is an effective instance. Whether it is too little, the web page won’t be seen as related. An excessive amount of and it is likely to be seen as key phrase stuffing.
- Anticipated sample: That is the place we would see an “upside-down parabola” form, which we’ll talk about extra within the subsequent part.
The difficulties of utilizing correlations
Whereas correlation evaluation may be extremely helpful, it comes with a number of challenges which might be essential to grasp.
Components in isolation vs. in tandem
After we look at rating components individually, we threat overlooking vital interactions between them.
As an illustration, think about an internet site with high-quality content material however fewer backlinks. It’d nonetheless outrank a web site with extra backlinks however decrease content material high quality.
This highlights the need of taking a look at a number of components collectively to get a real image of what influences rankings.
Instance of Google Rating components in parallel
Think about you might be evaluating the influence of varied rating components in your web site’s efficiency.
Let’s say you think about content material high quality, backlink amount and mobile-friendliness. Whereas every of those components individually contributes to your rating, their mixed impact is what actually issues.
A web site that excels in content material high quality and mobile-friendliness however has fewer backlinks would possibly nonetheless carry out properly because of the synergy between high-quality content material and a user-friendly cell expertise.
Overpowering rating components
It’s additionally essential to grasp that some rating components can enormously overpower others.
For instance, if an internet site has an exceptionally excessive variety of authoritative backlinks, this would possibly considerably enhance its rankings even when its content material high quality is average.
This dominance could make it difficult to see the influence of smaller components, corresponding to web page load velocity. As a result of the impact of the stronger issue overshadows the weaker one, a web site with wonderful backlinks won’t must focus as closely on bettering load velocity to see rating enhancements.
Quadratic nonlinear relationships
Some components have what we name an “upside-down parabola” form. Key phrase utilization is an ideal instance. Let’s say we’re analyzing the key phrase density of “finest trainers” in product critiques:
- 0% density: The web page seemingly gained’t rank in any respect for the time period.
- 0.5% density: This is likely to be excellent, serving to the web page rank properly.
- 1% density: Nonetheless good, possibly rating barely decrease.
- 2% density: Beginning to appear to be key phrase stuffing, rankings drop.
- 5% density: Seemingly seen as spam, rankings plummet.
If we plotted this, we’d see an upside-down U form, with one of the best rankings within the center and worse rankings at each extremes.
Analyzing non-linear components
To investigate components like this, we would must get artistic. As an alternative of wanting on the uncooked key phrase density, we may:
- Search for the min and max frequency within the top-ranking outcomes and correlate that as a substitute. This offers us a “candy spot” vary.
- Use a quadratic regression as a substitute of linear correlation, which might seize this parabolic relationship.
- Rework the info. For instance, we may calculate absolutely the distinction from the “excellent” density (say, 0.5%) and correlate that with rankings. This could present that being near the best in both course correlates with higher rankings.
Different points
Confounding variables: Generally, what appears to be like like a correlation is likely to be defined by one other issue completely. As an illustration, we would see a correlation between phrase rely and rankings, however this may very well be as a result of longer content material tends to be extra complete and worthwhile, not as a result of Google has a “phrase rely” issue.
Causation vs. correlation: Simply because two issues are correlated doesn’t imply one causes the opposite. For instance, we would see a correlation between the variety of social shares and rankings. However this doesn’t essentially imply social shares straight affect rankings; it may very well be that nice content material each ranks properly and will get shared extra.
Pattern dimension and variability: After we’re taking a look at a single SERP, we’re coping with a small pattern dimension, which might result in deceptive conclusions. It’s usually higher to research patterns throughout a number of SERPs in the identical area of interest.
Time lag: Some components might need a delayed impact on rankings. As an illustration, new backlinks would possibly take time to affect rankings, making it onerous to identify the correlation if we’re taking a look at present backlink numbers and present rankings.
By understanding these complexities, we will use correlation evaluation extra successfully, combining it with different analytical instruments and our search engine optimisation experience to attract significant conclusions about rating components.
Extra hurdles in correlation evaluation for search engine optimisation
Unknown algorithm weights: With out figuring out the precise weights Google assigns to various factors, our correlation evaluation could not precisely replicate their true significance.
Relevance results: Instruments like BM25, named entity recognition and TF-IDF try to quantify relevance, however how these work together with different components like backlinks may be advanced and tough to seize in a easy correlation evaluation.
Area-level metrics: The leaked data means that total area metrics could also be factored into the scoring algorithm. Since we’re solely wanting on the SERP itself and particular person web page components, these domain-level influences act as a black field that would dramatically change rankings.
Spurious correlations: It’s vital to bear in mind that correlation doesn’t suggest causation. Some components could present robust correlations however not truly be causal in figuring out rankings.
Correlated components: Many search engine optimisation components aren’t unbiased of one another, making it tough to isolate their particular person results via correlation evaluation alone.
These hurdles underscore why area data and experience are essential. Because the particular person conducting the evaluation, you want to have some concept of what you’ll count on these components to do to have the ability to interpret the outcomes meaningfully.
What’s a robust correlation in a SERP consequence?
Clearly a .99 correlation is nice, however given the interaction of so many variables when ought to we actually take discover of a rating issue and its significance?
Within the messy world of search engine optimisation, a 0.99 (or -.99) correlation could be suspiciously excessive. Extra realistically, we should always begin taking note of correlations round 0.2 to 0.5, particularly in the event that they’re constant throughout a number of analyses.
Consequently, when correlations emerge in search engine optimisation evaluation, they are typically a lot smaller than we would count on in additional easy relationships. This doesn’t diminish their significance, nonetheless.
Even these smaller correlations can present worthwhile insights into the components influencing search rankings, particularly when considered as a part of a broader sample fairly than in isolation.
Right here’s when it’s best to actually take discover:
- Repeatability: When you’re seeing related correlations for an element throughout completely different key phrases, time durations, or industries, it’s extra prone to be vital.
- Alignment with search engine optimisation data: If the correlation aligns with what we learn about search engine optimisation finest practices or Google’s said preferences, it’s extra prone to be significant.
The place can correlation assist past our search engine optimisation intuitions?
Now, you is likely to be considering, “That is all properly and good, however how does it truly assist me in the true world? Might’t I simply eyeball the search outcomes and see the components that matter?”
Nice query! Listed here are some sensible functions the place correlation evaluation can provide us further insights that transcend our intestine emotions.
- Ruling out the affect of some components: Generally, what we predict issues… doesn’t. For instance, you would possibly consider that utilizing exact-match key phrases in H2 tags is essential for rating. However while you run a correlation evaluation, you discover no important relationship between H2 key phrase utilization and rankings. This doesn’t imply H2 tags are ineffective, but it surely suggests they may not be as vital as you thought.
- Unveiling industry-specific rating components.
- Prioritizing search engine optimisation efforts.
- Measuring the influence of algorithm updates: When you monitor how correlations change with algorithm updates, it could actually assist level out which underlying components could have modified within the replace.
Superior methods and future instructions
Whereas correlation evaluation is a helpful first step in understanding rating components, extra superior methods may be utilized that may higher deal with the multivariate nature of rating components and the numerous various kinds of relationships rating components could have with scoring.
- Regression evaluation: This might help decide the relative significance of a number of components concurrently.
- Determination timber: These can seize non-linear relationships and interactions between components.
- Machine studying at scale: Combining correlation methods with machine studying can reveal advanced patterns throughout giant datasets.
Utilizing correlation evaluation to tell your search engine optimisation technique
Correlation evaluation is usually a highly effective software for SEOs searching for to grasp the relative significance of varied rating components. Nonetheless, it’s essential to method this evaluation with a stable understanding of statistical ideas, consciousness of the constraints and robust area experience.
By combining correlation evaluation with different superior methods and at all times grounding our interpretations in search engine optimisation finest practices, we will acquire worthwhile insights to tell our methods and choices.
Dig deeper: Analyze content publishing velocity with this Python script
Contributing authors are invited to create content material for Search Engine Land and are chosen for his or her experience and contribution to the search neighborhood. Our contributors work below the oversight of the editorial staff and contributions are checked for high quality and relevance to our readers. The opinions they specific are their very own.
[ad_2]
Source link