
[ad_1]
The previous decade has marked the shift of website positioning from spreadsheet-driven, anecdotal finest practices to a extra data-driven method, evidenced by the larger numbers of website positioning professionals studying Python.
As Google’s updates enhance in quantity (11 in 2023), website positioning professionals are recognizing the necessity to take a extra data-driven method to website positioning, and inside hyperlink buildings for site architectures are not any exception.
In a previous article, I outlined how inside linking might be extra data-driven, offering Python code on the right way to consider the positioning structure statistically.
Past Python, knowledge science can assist website positioning professionals extra successfully uncover hidden patterns and key insights to assist sign to search engines like google and yahoo the precedence of content material inside an internet site.
Knowledge science is the intersection of coding, math, and area information, the place the area, in our case, is website positioning.
So whereas math and coding (invariably in Python) are necessary, website positioning is on no account diminished in its significance, as asking the best questions of the information and having the instinctive really feel of whether or not the numbers “look proper” are extremely necessary.
Align Web site Structure To Help Underlinked Content material
Many websites are constructed like a Christmas tree, with the house web page on the very high (being a very powerful) and different pages in descending order of significance in subsequent ranges.
For the website positioning scientists amongst you, you’ll wish to know what the distribution of hyperlinks is from totally different views. This may be visualized utilizing the Python code from the earlier article in a number of methods, together with:
- Web site depth.
- Content material kind.
- Inner Web page Rank.
- Conversion Worth/Income.
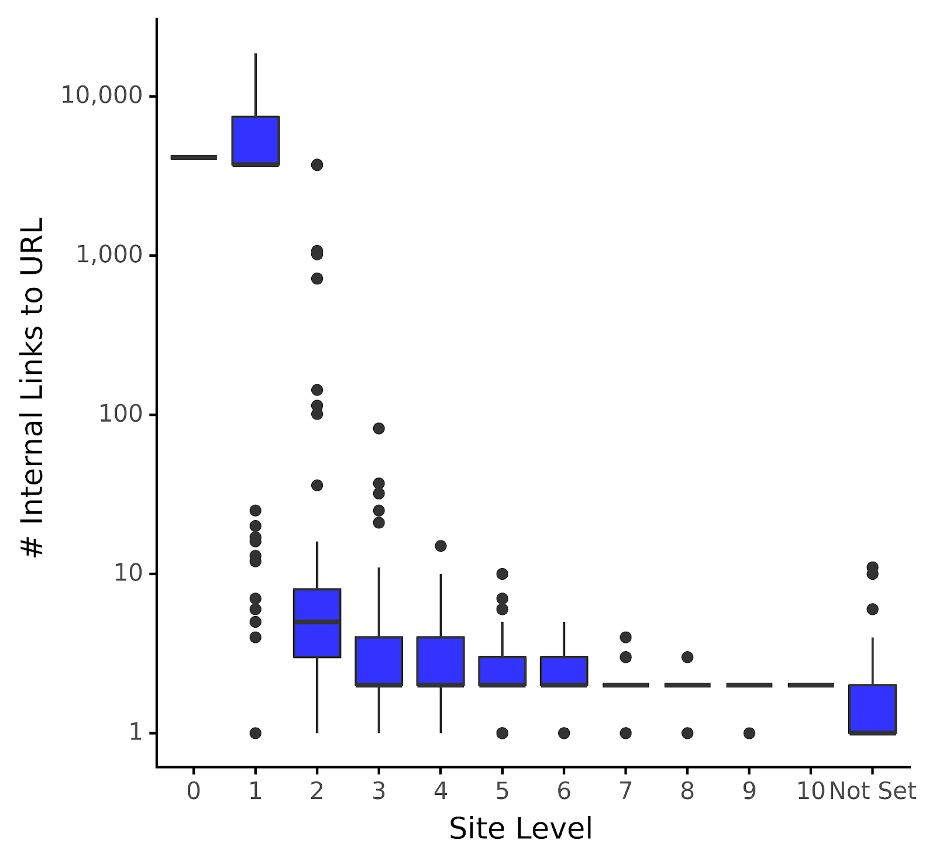
The boxplot successfully exhibits what number of hyperlinks are “regular” for a given web site at totally different website ranges. The blue packing containers symbolize the interquartile vary (i.e., the twenty fifth and seventy fifth quantiles) which is the place most (67% to be exact) of the variety of inbound inside hyperlinks lie.
Consider the bell curve, however as an alternative of viewing it from the facet (as you’d a mountain), you’re viewing it like a fowl flying overhead.
For instance, the chart exhibits that for pages which can be two ranges down from the house web page, the blue field signifies that 67% of URLs have between 5 and 9 inbound inside hyperlinks. We will additionally see that is significantly (and maybe unsurprisingly) a lot decrease than pages which can be one hop away from the house web page.
The thick line that cuts the blue field is the median (fiftieth quantile), representing the center worth. Going with the above instance, the median inbound inside hyperlinks are 7 for website degree 2 pages, which is about 5,000 instances lower than these in website degree 1!
On a facet be aware, you might discover that the median line isn’t seen for all blue packing containers, the reason is the information is skewed (i.e., not usually distributed like a bell-shaped curve).
Is This Good? Is This Unhealthy? Ought to website positioning Execs Be Frightened?
An information scientist with no information of website positioning would possibly determine that it’d be higher to redress the steadiness by figuring out the distribution of inside hyperlinks to pages by website degree.
From there, any pages which can be, say, under the median or the twentieth percentile (quantile in knowledge science converse) for his or her given website degree, an information scientist would possibly conclude that these pages require extra inside hyperlinks.
As such, this typically implies that pages that share the identical variety of hops from the house web page (i.e., similar website depth degree) are of equal significance.
Nevertheless, from a search worth perspective, that is unlikely to be true, particularly when you think about that some pages on the identical degree merely have extra search demand than others.
Thus, the positioning structure ought to prioritize these pages with extra search demand than these with much less demand no matter their default place within the hierarchy – no matter their degree!
Revising True Inner Web page Rank (TIPR)
True Internal Page Rank (TIPR), as popularised by Kevin Indig, has taken a moderately extra smart method by incorporating the exterior PageRank, i.e., earned from backlinks. In easy maths phrases:
TIPR = Inner Web page Rank x Web page Stage Authority of Backlinks
Though the above is the non-scientific model of his metric, it’s nonetheless a way more helpful and empirical approach of modeling what’s the regular worth of a web page’s worth inside an internet site structure. If you happen to’d just like the code to compute this, please see here.
Moreover, moderately than making use of this metric to website ranges, it’s much more instructive to use this by content material kind. For an ecommerce consumer, we see the distribution of TIPR by content material kind under:
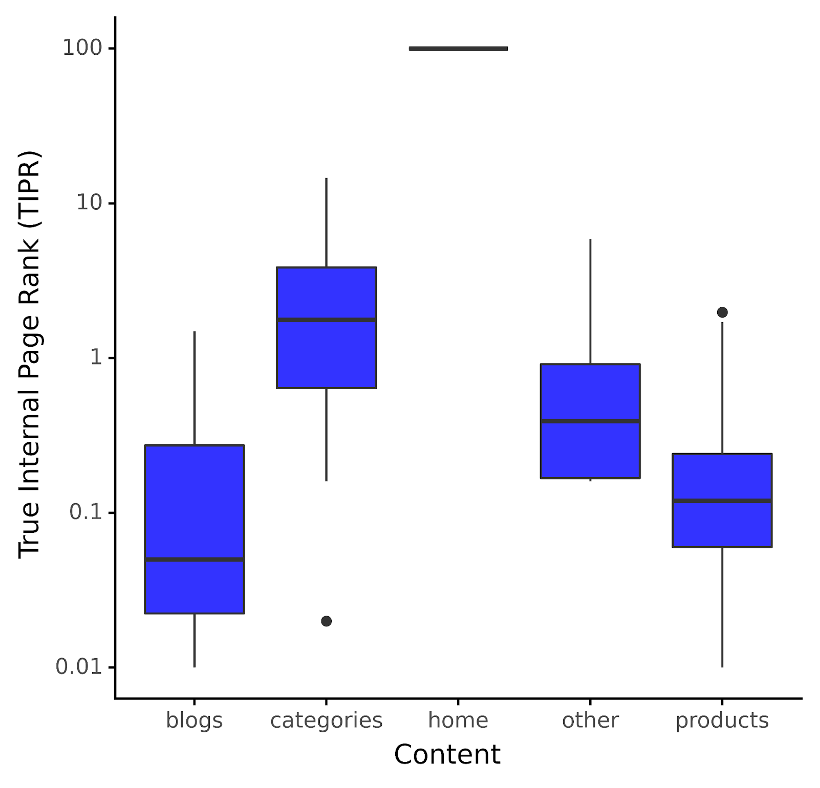 Picture by creator, December 2023
Picture by creator, December 2023The plot on this on-line retailer’s case is that the median TIPR for classes content material or Product Itemizing Pages (PLPs) is about two TIPR factors.
Admittedly, TIPR is a bit summary, as how does that translate to the quantity of inside hyperlinks required? It doesn’t – at the very least indirectly.
Abstraction however, that is nonetheless a simpler assemble for shaping website structure.
If you happen to needed to see which classes have been underperforming for his or her rank place potential, you’d merely see that PLP URLs have been under the twenty fifth quantile and maybe search for inside hyperlinks from pages of a better TIPR worth.
What number of hyperlinks and what TIPR? With some modeling, that’s a solution for an additional publish.
Introducing Income Inner Web page Rank (RIPR)
The opposite necessary query value answering is: which content material deserves increased rank positions?
Kevin additionally advocated a extra enlightened method to align inside hyperlink buildings in the direction of conversion values, which a lot of you might be hopefully already making use of to your shoppers; I need to heartily agree.
A easy non-scientific resolution is to take the ratio of the ecommerce income to the TIPR i.e.
RIPR = Income / TIPR
The above metric helps us see what regular income per web page authority seems to be like, as visualized under:
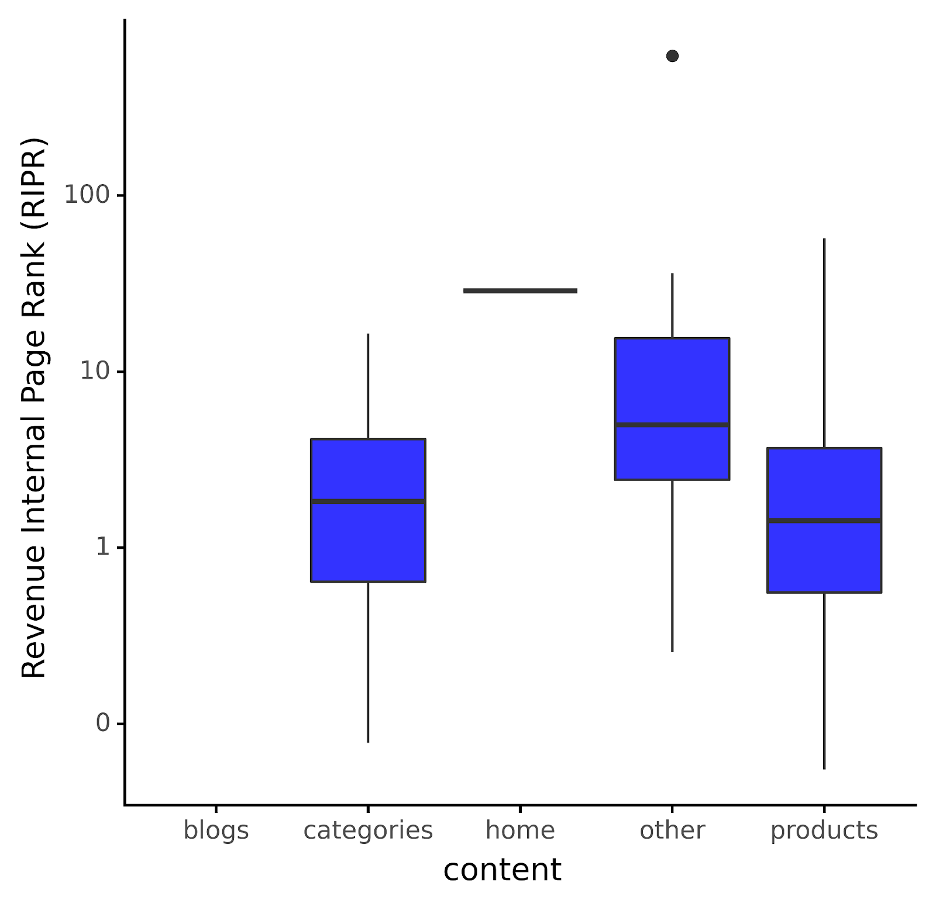 Picture by creator, December 2023
Picture by creator, December 2023As we will see, the image adjustments considerably; abruptly, we see no field (i.e., distribution) for weblog content material as a result of no income is recorded towards that content material.
Sensible functions? If we use this as a mannequin by content material kind, any pages which can be increased than the seventy fifth quantile (i.e., north of their blue field) for his or her respective content material kind ought to have extra inside hyperlinks added to them.
Why? As a result of they’ve excessive income however are very low in Web page Authority, which means they’ve a really excessive RIPR and may subsequently be given extra inside hyperlinks to get it nearer to the median.
In contrast, these with decrease income however too many important inside hyperlinks may have a decrease RIPR and may thus have hyperlinks taken away from them to permit the upper income content material to be assigned extra significance by the major search engines.
A Caveat
RIPR has some assumptions inbuilt, reminiscent of analytics income monitoring being arrange correctly in order that your mannequin kinds the premise for efficient inside hyperlink suggestions.
After all, as in TIPR, one ought to mannequin what an inside hyperlink is value by way of how a lot RIPR an inside hyperlink is value from any given web page.
That’s earlier than we even get to the situation of the interior hyperlink placement itself.
Extra assets:
Featured Picture: NicoElNino/Shutterstock
[ad_2]
Source link