
[ad_1]
Pandu Nayak testified on the U.S. vs. Google antitrust trial again in October. All I remembered seeing on the time was what felt like a PR puff piece revealed by the New York Times.
Then AJ Kohn revealed What Pandu Nayak taught me about SEO on Nov. 16 – which contained a hyperlink to a PDF of Nayak’s testimony. It is a fascinating learn for SEOs.
Learn on for my abstract of what Nayak revealed about how Google Search and rating works – together with indexing, retrieval, algorithms, rating programs, clicks, human raters and rather more – plus some further context from different antitrust trial displays that hadn’t been launched after I revealed 7 must-see Google Search ranking documents in antitrust trial exhibits.
Some elements will not be new to you, and this isn’t the complete image of Google Search – a lot has been redacted throughout the trial, so we’re doubtless lacking some context and different key particulars. Nevertheless, what’s right here is price digging into.
Google indexing
Google crawls the net and makes a replica of it. That is known as an index.
Consider an index you may discover on the finish of a ebook. Conventional data retrieval programs (serps) work equally after they lookup net paperwork.
However the net is ever-changing. Measurement isn’t the whole lot, Nayak defined, and there’s lots of duplication on the net. Google’s objective is to create a “complete index.”
In 2020, the index was “perhaps” about 400 billion paperwork, Nayak mentioned. (We realized that there was a time frame when that quantity got here down, although precisely when was unclear.)
- “I don’t know prior to now three years if there’s been a particular change within the measurement of the index.”
- “Greater just isn’t essentially higher, since you may fill it with junk.”
You may maintain the scale of the index the identical in the event you lower the quantity of junk in it,” Nayak mentioned. “Eradicating stuff that’s not good data” is one option to “enhance the standard of the index.”
Nayak additionally defined the function of the index in data retrieval:
- “So when you’ve got a question, that you must go and retrieve paperwork from the index that match the question. The core of that’s the index itself. Keep in mind, the index is for each phrase, what are the pages on which that phrase happens. And so — that is known as an inverted index for numerous causes. And so the core of the retrieval mechanism is trying on the phrases within the question, strolling down the listing — it’s known as the postings listing — and intersecting the postings listing. That is the core retrieval mechanism. And since you possibly can’t stroll the lists all the best way to the tip as a result of it is going to be too lengthy, you kind the index in such a method that the doubtless good pages, that are prime quality — so generally these are sorted by web page rank, for instance, that’s been achieved prior to now, are kind of earlier within the factor. And when you’ve retrieved sufficient paperwork to get it right down to tens of hundreds, you hope that you’ve got sufficient paperwork. So that is the core of the retrieval mechanism, is utilizing the index to stroll down these postings lists and intersect them so that each one the phrases within the question are retrieved.”
Google rating
We all know Google makes use of the index to retrieve pages matching the question. The issue? Hundreds of thousands of paperwork may “match” many queries.
This is the reason Google makes use of “tons of of algorithms and machine studying fashions, none of that are wholly reliant on any singular, giant mannequin,” in line with a blog post Nayak wrote in 2021.
These algorithms and machine studying fashions basically “cull” the index to essentially the most related paperwork, Nayak defined.
- “In order that’s — the following part is to say, okay, now I’ve received tens of hundreds. Now I’m going to make use of a bunch of indicators to rank them in order that I get a smaller set of a number of hundred. After which I can ship it on for the following part of rating which, amongst different issues, makes use of the machine studying.”
Google’s A guide to Google Search ranking systems incorporates many rating programs you’re most likely nicely conversant in by now (e.g., BERT, useful content material system, PageRank, opinions system).
However Nayak (and different antitrust trial displays) have revealed new, beforehand unknown programs, for us to dig deeper into.
‘Perhaps over 100’ rating indicators
A few years in the past, Google used to say it used greater than 200 indicators to rank pages. That quantity ballooned briefly to 10,000 ranking factors in 2010 (Google’s Matt Cutts defined at one level that lots of Google’s 200+ indicators had greater than 50 variations inside a single issue) – a stat most individuals have forgotten.
Properly, now the variety of Google indicators is right down to “perhaps over 100,” in line with Nayak’s testimony.
What’s “maybe” an important sign (which matches what Google’s Gary Illyes said at Pubcon this 12 months) for retrieving paperwork is the doc itself, Nayak mentioned.
- “All of our core topicality indicators, our web page rank indicators, our localization indicators. There’s every kind of indicators in there that take a look at these tens of hundreds of paperwork and collectively create a rating that you then extract the highest few hundred from there,” Nayak mentioned.
The important thing indicators, in line with Nayak, are:
- The doc (a.ok.a., “the phrases on the web page and so forth”).
- Topicality.
- Web page high quality.
- Reliability.
- Localization.
- Navboost.
Right here’s the complete quote from the trial:
- “I imply, total, there’s lots of indicators. , perhaps over 100 indicators. However for retrieving paperwork, the doc itself is probably an important factor, these postings lists that we’ve that we use to retrieve paperwork from. That’s maybe an important factor, to get it right down to the tens of hundreds. After which after that, there are a lot of elements, once more. There are kind of code IR kind, data retrieval kind algorithms which cull topicality and issues, that are actually necessary. There may be web page high quality. The reliability of outcomes, that’s one other huge issue. There’s localization kind issues that go on there. And there may be navboost additionally in that.”
Google core algorithms
Google makes use of core algorithms to scale back the variety of matches for a question right down to “a number of hundred” paperwork. These core algorithms give the paperwork preliminary rankings or scores.
Every web page that matches a question will get a rating. Google then kinds the scores, that are utilized in half for Google to current to the person.
Internet outcomes are scored utilizing an IR rating (IR stands for data retrieval).
Navboost system (a.ok.a., Glue)
Navboost “is among the necessary indicators” that Google has, Nayak mentioned. This “core system” is concentrated on net outcomes and is one you gained’t discover on Google’s information to rating programs. Additionally it is known as a memorization system.
The Navboost system is skilled on person information. It memorizes all of the clicks on queries from the previous 13 months. (Earlier than 2017, Navboost memorized historic person clicks on queries for 18 months.)
The system dates again at the very least to 2005, if not earlier, Nayak mentioned. Navboost has been up to date over time – it isn’t the identical because it was when it was first launched.
- “Navboost is taking a look at lots of paperwork and determining issues about it. So it’s the factor that culls from lots of paperwork to fewer paperwork,” Nayak mentioned.
Attempting to not decrease the significance of Navboost, Nayak additionally made it clear that Navboost is only one sign Google makes use of. Nayak was requested whether or not Navboost is “the one core algorithm that Google makes use of to retrieve outcomes,” and he mentioned “no, completely not.”
Navboost helps scale back paperwork to a smaller set for Google’s machine studying programs – however it could’t assist with rating for any “paperwork that don’t have clicks.”
Navboost slices
Navboost can “slice locale data” (i.e., the origin location of a question) and the info data that it has in it by locale.
When discussing “the primary culling” of “native paperwork” and the significance of retrieving companies which are near a searcher’s explicit location (e.g., Rochester, N.Y.), Google is presenting them to the person “to allow them to work together with it and create Navboost and so forth.”
- “Keep in mind, you get Navboost solely after they’re retrieved within the first place,” Nayak mentioned.
So this implies Navboost is a rating sign that may solely exist after customers have clicked on it.
Navboost can even create totally different datasets (slices) for cell vs. desktop searches. For every question, Google tracks what sort of machine it’s made on. Location issues whether or not the search is carried out by way of desktop or cell – and Google has a particular Navboost for cell.
- “It’s one of many slices,” Nayak mentioned.
Glue
What’s Glue?
“Glue is simply one other identify for Navboost that features the entire different options on the web page,” in line with Nayak, confirming that Glue does the whole lot else on the Google SERP that’s not net outcomes.
Glue was additionally defined in a distinct exhibit (Prof. Douglas Oard Presentation, Nov. 15, 2023):
- “Glue aggregates numerous forms of person interactions–equivalent to clicks, hovers, scrolls, and swipes–and creates a standard metric to check net outcomes and search options. This course of determines each whether or not a search function is triggered and the place it triggers on the web page.”
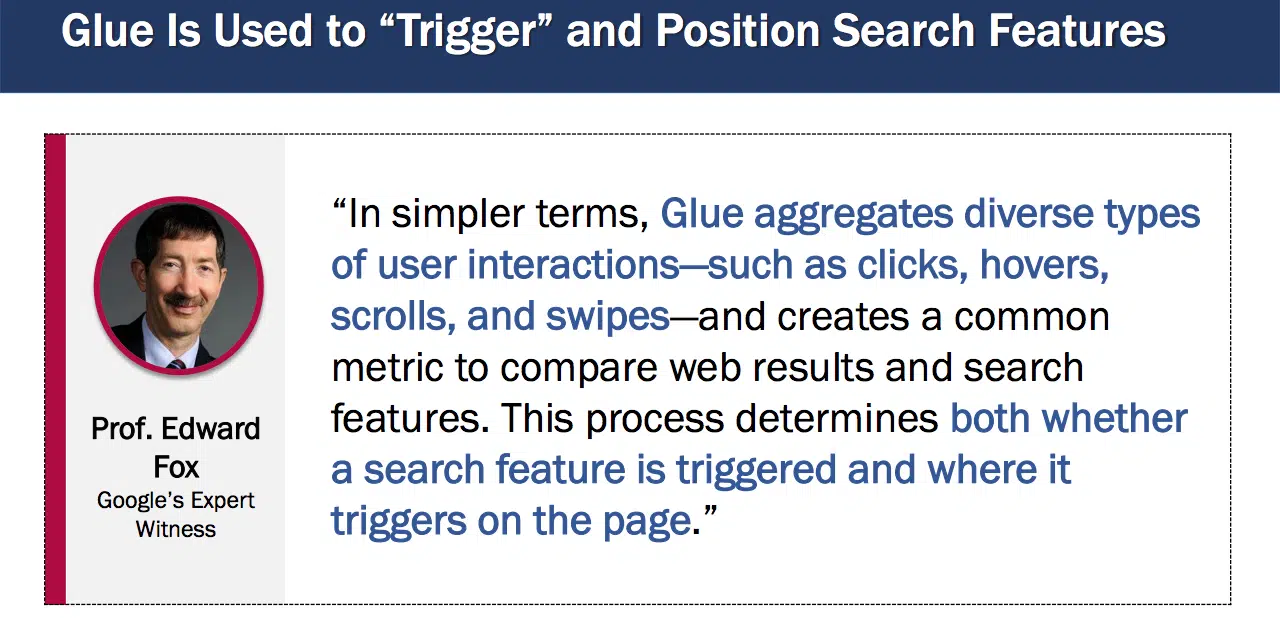
Additionally, as of 2016, Glue was necessary to Entire-Web page Rating at Google:
- “Consumer interplay information from Glue is already being utilized in Internet, KE [Knowledge Engine], and WebAnswers. Extra just lately, it is among the vital indicators in Tetris.”

We additionally realized about one thing known as Instantaneous Glue, described in 2021 as a “realtime pipeline aggregating the identical fractions of user-interaction indicators as Glue, however solely from the final 24 hours of logs, with a latency of ~10 minutes.”

Navboost and Glue are two indicators that assist Google discover and rank what in the end seems on the SERP.
Deep studying programs
Google “began utilizing deep studying in 2015,” in line with Nayak (the 12 months RankBrain launched).
As soon as Google has a smaller set of paperwork, then the deep studying can be utilized to regulate doc scores.
Some deep studying programs are additionally concerned within the retrieval course of (e.g., RankEmbed). A lot of the retrieval course of occurs beneath the core system.
Will Google Search ever belief its deep studying programs totally for rating? Nayak mentioned no:
- “I feel it’s dangerous for Google — or for anybody else, for that matter, to show over the whole lot to a system like these deep studying programs as an end-to-end top-level operate. I feel it makes it very onerous to regulate.”
Nayak mentioned three major deep studying fashions Google makes use of in rating, in addition to how MUM is used.
RankBrain:
- Appears to be like on the high 20 or 30 paperwork and will alter their preliminary rating.
- Is a dearer course of than a few of Google’s different rating parts (it’s too costly to run on tons of or hundreds of outcomes).
- Is skilled on queries throughout all languages and locales Google operates in.
- Is okay-tuned on IS (Information Satisfaction) ranking information.
- Can’t be skilled on solely human rater information.
- RankBrain is all the time retrained with contemporary information (for years, RankBrain was skilled on 13 months’ price of click on and question information).
- “RankBrain understands long-tail person want because it trains…” Nayak mentioned.
DeepRank:
- Is BERT when BERT is used for rating.
- Is taking over extra of RankBrain’s functionality.
- Is skilled on person information.
- Is okay-tuned on IS ranking information.
- Understands language and has widespread sense, in line with a doc learn to Nayak throughout the trial. As quoted throughout Nayak’s testimony from a DeepRank doc:
- “DeepRank not solely offers important relevance positive aspects, but additionally ties rating extra tightly to the broader discipline of language understanding.”
- “Efficient rating appears to require some quantity of language understanding paired with as a lot world data as potential.”
- “Typically, efficient language understanding appears to require deep computation and a modest quantity of knowledge.”
- “In distinction, world data is all about information; the extra the higher.”
- “DeepRank appears to have the capability to be taught the understanding of language and commonsense that raters depend on to guesstimate relevance, however not almost sufficient capability to be taught the huge quantity of world data wanted to fully encode person preferences.”
DeepRank wants each language understanding and world data to rank paperwork, Nayak confirmed. (“The understanding language results in rating. So DeepRank does rating additionally.”) Nevertheless, he indicated DeepRank is a little bit of a “black field”:
- “So it’s realized one thing about language understanding, and I’m assured it realized one thing about world data, however I’d be hard-pressed to present you a crisp assertion on these. These are kind of inferred form of issues,” Nayak defined.
What precisely is world data and the place does DeepRank get it? Nayak defined:
- “One of many attention-grabbing issues is you get lots of world data from the net. And right now, with these giant language fashions which are skilled on the net — you’ve seen ChatGPT, Bard and so forth, they’ve lots of world data as a result of they’re skilled on the net. So that you want that information. They know every kind of particular details about it. However you want one thing like this. In search, you will get the world data as a result of you’ve got an index and also you retrieve paperwork, and people paperwork that you just retrieve offers you world data as to what’s happening. However world data is deep and complex and sophisticated, and in order that’s — you want some option to get at that.”
RankEmbed BERT:
- Was initially launched earlier, with out BERT.
- Augmented (and renamed) to make use of the BERT algorithm “so it was even higher at understanding the language.”
- Is skilled on paperwork, click on and question information.
- Is okay-tuned on IS ranking information.
- Must be retrained in order that the coaching information displays contemporary occasions.
- Identifies further paperwork past these recognized by conventional retrieval.
- Skilled on a smaller fraction of site visitors than DeepRank – “having some publicity to the contemporary information is definitely fairly precious.”
MUM:
MUM is one other costly Google mannequin so it doesn’t run for each question at “run time,” Nayak defined:
- “It’s too huge and too sluggish for that. So what we do there may be to coach different smaller fashions utilizing the particular coaching, just like the classifier we talked about, which is a a lot less complicated mannequin. And we run these less complicated fashions in manufacturing to serve the use circumstances.”
QBST and Time period weighting
QBST (Question Based mostly Salient Phrases) and time period weighting are two different “rating parts” Nayak was not requested about. However these appeared in two slides of the Oard exhibit linked earlier.

These two rating integrations are skilled on ranking information. QBST, like Navboost, was known as a memorization system (that means it probably makes use of question and click on information). Past their existence, we realized little about how they work.
The time period “memorization programs” can also be talked about in an Eric Lehman email. It could simply be one other time period for Google’s deep studying programs:
- “Relevance in net search could not fall shortly to deep ML, as a result of we depend on memorization programs which are a lot bigger than any present ML mannequin and seize a ton of seemingly-crucial data about language and the world.”
Assembling the SERP
Search options are all the opposite components that seem on the SERP that aren’t the net outcomes. These outcomes additionally “get a rating.” It was unclear from the testimony if it’s an IR Rating or a distinct form of rating.
The Tangram system (previously referred to as Tetris)
We realized a bit about Google’s Tangram system, which was once known as Tetris.
The Tangram system provides search options that aren’t retrieved via the net, primarily based on different inputs and indicators, Nayak mentioned. Glue is a type of indicators.
You may see a high-level overview of how Freshness in Tetris labored in 2018, in a slide from the Oard trial exhibit:
- Applies Instantaneous Glue in Tetris.
- Demotes or suppresses stale options for fresh-deserving queries; promotes TopStories.
- Indicators for newsy queries.

Evaluating the SERP and Search outcomes
The IS Rating is Google’s main top-level metric of Search high quality. That rating is computed from search high quality rater rankings. It’s “an approximation of person utility.”
IS is all the time a human metric. The rating comes from 16,000 human testers all over the world.

“…One factor that Google may do is take a look at queries for inspiration on what it would want to enhance on. … So we create samples of queries that – on which we consider how nicely we’re doing total utilizing the IS metric, and we take a look at – usually we take a look at queries which have low IS to try to perceive what’s going on, what are we lacking right here…In order that’s a method of determining how we are able to enhance our algorithms.”
Nayak offered some context to present you a way of what some extent of IS is:

“Wikipedia is a extremely necessary supply on the net, a number of nice data. Folks prefer it lots. If we took Wikipedia out of our index, fully out of our index, then that may result in an IS lack of roughly a couple of half level. … A half level is a fairly important distinction if it represents the entire Wikipedia wealth of data there…”
IS, rating and search high quality raters
Generally, IS-scored paperwork are used to coach the totally different fashions within the Google search stack. As famous within the Rating part, IS rater information helps practice a number of deep studying programs Google makes use of.
Whereas particular customers will not be happy with IS enchancment, “[Across the corpus of Google users] it seems that IS is nicely correlated with helpfulness to customers at giant,” Nayak mentioned.
Google can use human raters to “quickly” experiment with any rating change, Nayak mentioned in his testimony.
- “Adjustments don’t change the whole lot. That wouldn’t be an excellent state of affairs to have. So most modifications change a couple of outcomes. Perhaps they modify the ordering of outcomes, during which case you don’t even need to get new scores, or generally they add new outcomes and also you get scores for these. So it’s a really highly effective method of having the ability to iterate quickly on experimental modifications.”
Nayak additionally offered some extra insights into how raters assign scores to question units:
- “So we’ve question units created in numerous methods as samples of our question stream the place we’ve outcomes which have been rated by raters. And we use this — these question units as a method of quickly experimenting with any rating change.”
- “Let’s say we’ve a question set of let’s say 15,000 queries, all proper. We take a look at all the outcomes for these 15,000 queries. And we get them rated by our raters.”
- “These are always working on the whole, so raters have already given scores for a few of them. You may run an experiment that brings up further outcomes, and you then’d get these rated.”
- “Lots of the outcomes that they produce we have already got scores from the previous. And there might be some outcomes that they gained’t have scores on. So we’ll ship these to raters to say inform us about this. So now all the outcomes have scores once more, and so we’ll get an IS rating for the experimental set.”
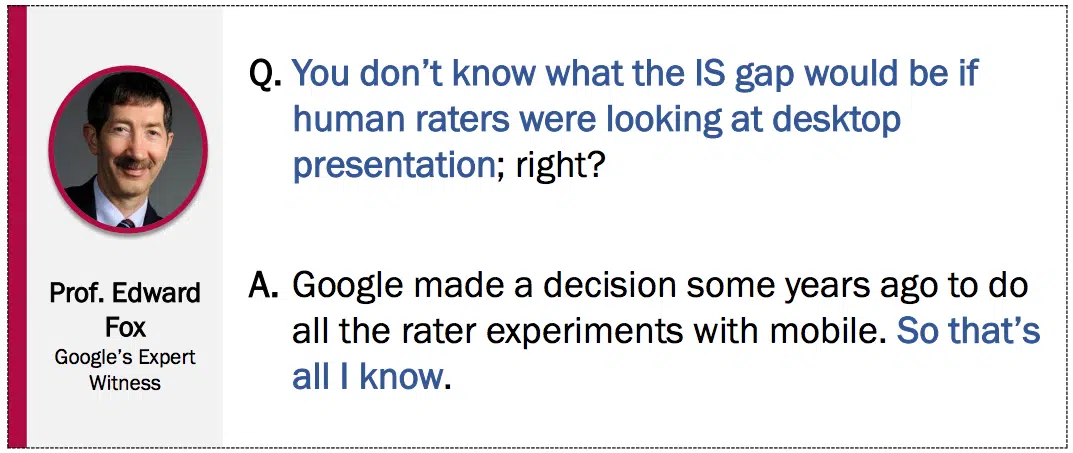
One other attention-grabbing discovery: Google determined to do all rater experiments with cell, in line with this slide:
Issues with raters
Human raters are requested to “put themselves within the sneakers of the standard person that could be there.” Raters are purported to signify what a normal person is in search of. However “each person clearly comes with an intent, which you’ll be able to solely hope to guess,” Nayak mentioned.
Paperwork from 2018 and 2021 spotlight a couple of points with human raters:
- Raters could not perceive technical queries.
- Raters cannot precisely choose the recognition of something.
- In IS Scores, human raters don’t all the time pay sufficient consideration to the freshness facet of relevance or lack the time context for the question, thus undervaluing contemporary outcomes for fresh-seeking queries.

A slide from a presentation (Unified Click Prediction) signifies that a million IS scores are “greater than adequate to fantastically tune curves by way of RankLab and human judgment” however give “solely a low-resolution image of how individuals work together with search outcomes.”

Different Google Search analysis metrics
A slide from 2016 revealed that Google Search High quality makes use of 4 different major metrics to seize person intent, along with IS:
- PQ (web page high quality)
- Aspect-by-Sides
- Reside experiments
- Freshness

On Reside Experiments:
- All Rating experiments run LE (if potential)
- Measures place weighted lengthy clicks
- Eval workforce now utilizing consideration as nicely
On Freshness:
“One necessary facet of freshness is guaranteeing that our rating indicators mirror the present state of the world.” (2021)
All of those metrics are used for sign growth, launches and monitoring.
Studying from customers
So, if IS solely offers a “low-resolution image of how individuals work together with search outcomes,” what offers a clearer image?
Clicks.
No, not particular person clicks. We’re speaking about trillions of examples of clicks, in line with the Unified Click on Prediction presentation.

Because the slide signifies:
“~100,000,000,000 clicks
present a vastly clearer image of how individuals work together with search outcomes.
A conduct sample obvious in only a few IS scores could also be mirrored in tons of of hundreds of clicks, permitting us to be taught second and third order results.”
Google illustrates an instance with a slide:

- Click on information signifies that paperwork whose title incorporates dvm are presently under-ranked for queries that begin with [dr …]
- dvm = Physician of Veterinary Medication
- There are a pair related examples within the 15K set.
- There are about 1,000,000 examples in click on information.
- So the quantity of click on information for this particular state of affairs roughly equals the overall quantity of all human ranking information.
- Studying this affiliation just isn’t solely potential from the coaching information, however required to reduce the target operate.
Clicks in rating
Google appears to equate utilizing clicks with memorizing moderately than understanding the fabric. Like how one can learn a complete bunch of articles about search engine marketing however probably not perceive how you can do search engine marketing. Or how studying a medical ebook doesn’t make you a physician.
Let’s dig deeper into what the Unified Click on Prediction presentation has to say about clicks in rating:

- Reliance on person suggestions (“clicks”) in rating has steadily elevated over the previous decade.
- Exhibiting outcomes that customers need to click on is NOT the last word objective of net rating. This could:
- Promote low-quality, click-bait outcomes.
- Promote outcomes with real enchantment that aren’t related.
- Be too forgiving of optionalization.
- Demote official pages, promote porn, and many others.
Google’s objective is to determine what customers will click on on. However, as this slide reveals, clicks are a proxy goal:

- However exhibiting outcomes that customers need to click on is CLOSE to our objective.
- And we are able to do that “nearly proper” factor extraordinarily nicely by drawing upon trillions of examples of person conduct in search logs.
- This means a technique for bettering search high quality:
- Predict what outcomes customers will click on.
- Increase these outcomes.
- Patch up issues with web page high quality, relevance, optionalization, and many others.
- Not a radical thought. We’ve achieved this for years.
The subsequent three slides dive into click on prediction, all titled “Life Contained in the Crimson Triangle.” Right here’s what Google’s slides inform us:

- The “interior loop” for individuals engaged on click on prediction turns into tuning on person suggestions information. Human analysis is utilized in system-level testing.
- We get about 1,000,000,000 new examples of person conduct day-after-day, allowing high-precision analysis, even in smaller locales. The check is:
Have been your click on predictions higher or worse than the baseline?
- It is a fully-quantifiable goal, in contrast to the bigger downside of optimizing search high quality. The necessity to steadiness a number of metrics and intangibles is essentially pushed downstream.

- The analysis methodology is “practice on the previous, predict the long run”. This largely eliminates issues with over-fitting to coaching information.
- Steady analysis is on contemporary queries and the stay index. So the significance of freshness is constructed into the metric.
- The significance of localization and additional personalization are additionally constructed into the metric, for higher or worse.

- This refactoring creates a monstrous and interesting optimization downside: use tons of of billions of examples of previous person conduct (and different indicators), to foretell future conduct involving an enormous vary of subjects.
- The issue appears too giant for any present machine studying system to swallow. We’ll doubtless want some mixture of handbook work, RankLab tuning, and large-scale machine studying to attain peak efficiency.
- In impact, the metric quantifies our means to emulate a human searcher. One can hardly keep away from reflections on the Turing Take a look at and Searle’s Chinese language Room.
- Shifting from hundreds of coaching examples to billions is game-changing…
Consumer suggestions (i.e., click on information)
Each time Google talks about amassing person information for X variety of months, that’s all “the queries and the clicks that occurred over that time frame,” from all customers, Nayak mentioned.
If Google have been launching only a U.S. mannequin, it might practice its mannequin on a subset of U.S. customers, for instance, Nayak mentioned. However for a world mannequin, it’s going to take a look at the queries and clicks of all customers.
Not each click on in Google’s assortment of session logs has the identical worth. Additionally, more energizing person, click on and question information just isn’t higher in all circumstances.
- “It relies on the question … there are conditions the place the older information is definitely extra precious. So I feel these are all kind of empirical inquiries to say, nicely, what precisely is occurring. There are clearly conditions the place contemporary information is healthier, however there are additionally circumstances the place the older information is extra precious,” Nayak mentioned.
Beforehand, Nayak mentioned there’s a level of diminishing returns:
“…And so there may be this trade-off by way of quantity of knowledge that you just use, the diminishing returns of the info, and the price of processing the info. And so often there’s a candy spot alongside the best way the place the worth has began diminishing, the prices have gone up, and that’s the place you’d cease.”

The Priors algorithm
No, the Priors algorithm just isn’t an algorithm replace, like a useful content material, spam or core replace. In these two slides, Google highlighted its tackle “the selection downside.”

“The thought is the rating the doorways primarily based on how many individuals took it.
In different phrases, you rank the alternatives primarily based on how fashionable it’s.
That is easy, but very highly effective. It is among the strongest indicators for a lot of Google’s search and advertisements rating! If we all know nothing concerning the person, that is most likely the perfect factor we are able to do.”
Google explains its personalised “twist” – taking a look at who went via every door and what actions describe them – within the subsequent slide:

“We convey two twists to the standard heuristic.
As a substitute of making an attempt to explain – via a loud course of – what every door is about, we describe it primarily based on the individuals who took it.
We are able to do that at Google, as a result of at our scale, even essentially the most obscure alternative would have been exercised by hundreds of individuals.
When a brand new person walks in, we measure their similarity to the individuals behind every door.
This brings us to the second twist, which is that whereas describing a person, we don’t not [sic] use demographics or different stereotypical attributes.
We merely use a person’s previous actions to explain them and match customers primarily based on their behavioral similarity.”
The ‘information community impact’
One ultimate tidbit comes from Hal Varian email that was launched as a trial exhibit.
The Google we all know right now is a results of a mixture of numerous algorithm tweaks, thousands and thousands of experiments and invaluable learnings from end-user information. Or, as Varian wrote:
“One of many subjects that comes up always is the ‘information community impact’ which argues that
Top quality => extra customers => extra evaluation => prime quality
Although this is kind of proper, 1) it applies to each enterprise, 2) the ‘extra evaluation’ ought to actually be ‘extra and higher evaluation”.
A lot of Google’s enchancment over time has been resulting from hundreds of individuals … figuring out tweaks which have added as much as Google as it’s right now.
It is a little too subtle for journalists and regulators to acknowledge. They imagine that if we simply handed Bing a billion long-tail queries, they might magically develop into lots higher.”
[ad_2]
Source link